c# - Buffers de protocolo versus JSON o BSON
comparison protocol-buffers (4)
Estos son algunos puntos de referencia recientes que muestran el rendimiento de los Serializadores .NET populares.
Los puntos de referencia de Burning Monks muestran el rendimiento de la serialización de un POCO simple, mientras que los puntos de referencia integrales de Northwind muestran los resultados combinados de la serialización de una fila en cada tabla del conjunto de datos Northwind de Microsoft.
Básicamente, los búferes de protocolo ( protobuf-net ) son alrededor de 7 protobuf-net más rápidos que el Serializador de biblioteca de clase Base más rápido en .NET (XML DataContractSerializer). También es más pequeño que la competencia, ya que también es 2,2 veces más pequeño que el formato de serialización más compacto de Microsoft (JsonDataContractSerializer).
Los serializadores de texto de ServiceStack son los más cercanos para igualar el rendimiento de la protobuf-net binaria, donde su serializador Json es solo 2.58x más lento que protobuf-net.
¿Alguien tiene alguna información sobre las características de rendimiento de Protocol Buffers frente a BSON (JSON binario) o frente a JSON en general?
- Tamaño del cable
- Velocidad de serialización
- Velocidad de deserialización
Estos parecen buenos protocolos binarios para usar a través de HTTP. Me pregunto qué sería mejor a largo plazo para un entorno C #.
Aquí hay algo de información que estaba leyendo en BSON y Protocol Buffers .
Los búferes de protocolo están diseñados para el cable:
- tamaño de mensaje muy pequeño: un aspecto es una representación entera de tamaño variable muy eficiente.
- Decodificación muy rápida: es un protocolo binario.
- protobuf genera C ++ super eficiente para codificar y decodificar los mensajes - sugerencia: si codificas todos los enteros var o elementos de tamaño estático, se codificará y decodificará a una velocidad determinística.
- Ofrece un modelo de datos MUY rico, que codifica de manera eficiente estructuras de datos muy complejas.
JSON es solo texto y necesita ser analizado . sugerencia: codificar un "mil millones" de int dentro de él tomaría un montón de caracteres: mil millones = 12 caracteres (escala larga), en binario se ajusta en uint32_t ¿Y qué hay sobre tratar de codificar un doble? eso sería mucho peor.
Thrift es otra alternativa similar a Protocol Buffers.
Hay buenos puntos de referencia de la comunidad Java sobre serialización / deserialización y tamaño de cable de estas tecnologías: http://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking
En general, JSON tiene un tamaño de cable ligeramente más grande y DeSer ligeramente peor, pero gana en ubicuidad y la capacidad de interpretarlo fácilmente sin el IDL de origen. El último punto es algo que Apache Avro está tratando de resolver, y supera a ambos en términos de rendimiento.
Microsoft lanzó un paquete C # NuGet Microsoft.Hadoop.Avro .
Esta publicación compara velocidades y tamaños de serialización en .NET, incluidos JSON, BSON y XML.
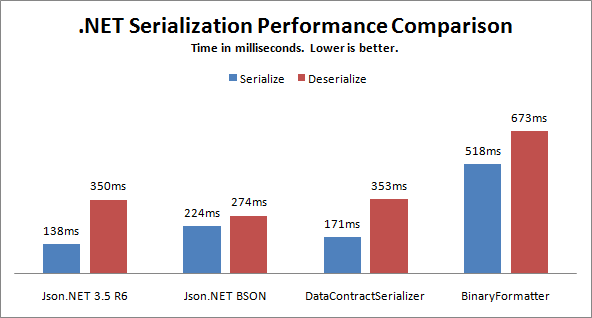{kind=link}
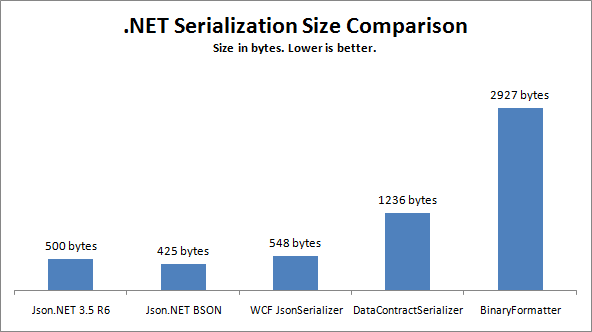{kind=link}
http://james.newtonking.com/archive/2010/01/01/net-serialization-performance-comparison.aspx