ocr - library - Se necesita consejo de escaneo de recibos de Tesseract
tesseract ocr python install (2)
He luchado de nuevo con Tesseract para varios proyectos de OCR y encontré un caso de uso hoy que pensé que sería un éxito para él, pero después de muchas horas todavía me estoy volviendo insatisfecho. Quería plantear el problema aquí y ver si alguien más tiene consejos sobre cómo resolver esta tarea.
Mi esposa vino a verme esta mañana y me preguntó si había alguna manera que pudiera escanear fácilmente sus recibos de Wal-Mart y, con el tiempo, construir un historial de precios gastados en categorías y artículos específicos para que pudiéramos hacer algunas tendencias y bucear con facilidad. a donde va el gasto Al principio sentí que esto era una tarea muy difícil, pero después de cavar un poco encontré algunas cosas que me hacen sentir que está al alcance de la mano:
Los recibos de Wal-Mart son, en general, muy bien estructurados y fáciles de leer. Incluso incluyen el UPC para cada artículo (¿posibilidad de búsquedas en una base de datos del UPC?) Y parecen clasificar los alimentos con una F o I (no estoy seguro de cuál es la diferencia) y también tienen una columna de código de impuestos que puede resultar útil Aprendo los secretos de lo que significan los códigos.
Además, descubrí que hay algún tipo de API de búsqueda de elementos de Wal-Mart a la que puedo acceder y que podría ser útil en la búsqueda de UPC.
Tienen una aplicación para teléfonos inteligentes que le permite escanear un código QR impreso en cada recibo. Esa aplicación busca un código "TC" en el recibo y extrae todo el recibo detallado de sus servidores. Le muestra una excelente representación gráfica del recibo, que incluye imágenes en miniatura de todos los elementos y el costo, etc. Si esta aplicación simplemente categorizara y resumiera el recibo, ¡ya estaría listo! Pero ay, ese no es el propósito de la aplicación ...
La última pieza del rompecabezas es que puede exportar una imagen PNG generada por computadora del recibo en caso de que quiera guardarlo y tirar la versión en papel. Para mí, este es el dinero que se inyecta, ya que estos PNG están creados por computadora y, por lo tanto, no están sujetos a los problemas relacionados con la toma de una fotografía o el escaneo de un recibo en papel.
A continuación, se muestra un ejemplo de uno de estos (editado ligeramente para eliminar algunas áreas pero exactamente como se obtiene de la aplicación):
https://postimg.cc/image/s56o0wbzf/
Puedes ver que la parte importante del texto está perfectamente alineada en 5 columnas y de eso se trata esta pregunta. Cómo hacer que Tesseract haga una OCR precisa en texto. Tengo muchas ideas sobre dónde llevarlo desde aquí, ¡pero todo comienza con el OCR!
Lo más cerca que he estado es este ejemplo aquí:
Usé psm6 y un juego de limitación de caracteres para forzarlo a hacer mayúsculas + números + solo algunos símbolos:
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
A primera vista, el OCR parece casi coincidir. Pero a medida que profundices, verás que falla de manera bastante horrible. 3s y 8s son casi siempre incorrectos. Lo mismo con 6s y 5s. Luego, hay veces que simplemente omite completamente los caracteres o simplemente comienza a desmoronarse (como la línea 31+ en el ejemplo). Comienza a ver 2s como 1s, o incluso simplemente falta caracteres. El SO PIZZA en la línea 33 debe ser "2.82" pero sale como "32".
He intentado hacer un procesamiento previo en la imagen para engrosar los caracteres y asegurarme de que sea en blanco y negro, pero ninguno de mis esfuerzos se acercó más que la imagen en bruto de Wal-Mart + los comandos anteriores.
Idealmente, ya que este es un PNG bien estructurado que presumiblemente siempre tiene el mismo ancho que me encantaría si pudiera definir las columnas por ancho de píxel para que Tesseract tratara cada columna de forma independiente. Intenté investigar esto, pero los archivos UZN que he visto mencionados no se traducen en anchos de píxel y parecen que la altura es un factor que no funcionaría en estos ya que la altura siempre será variable.
Además, necesito descubrir cómo entrenar a Tesseract para que reconozca los números con una precisión del 100% (las letras no son realmente importantes). Comencé a investigar cómo entrenar el programa pero, para ser honesto, se me pasó por alto rápidamente, ya que el alcance de la capacitación en la documentación es más para que reconozca idiomas completos, no solo 10 dígitos.
La solución final para el juego final sería una cadena de comandos que tomara el PNG original de la aplicación y me devolviera un CSV con las 5 columnas de datos de la parte importante del recibo. No espero eso fuera de esta pregunta, pero cualquier ayuda que me guíe hacia esto sería muy apreciada. En este punto, simplemente no tengo ganas de ser azotado por Tesseract una vez más, ¡así que estoy decidido a encontrar una manera de dominarla!
El reconocimiento de texto en los recibos es uno de los problemas más difíciles de manejar para OCR.
Las razones son numerosas:
- Los recibos se imprimen en papel barato con impresoras baratas, ¡para que sean baratas, no legibles!
- tienen una gran cantidad de texto denso (especialmente recibos de Wall-Mart)
- Los motores OCR existentes están capacitados casi exclusivamente en datos sin recibo (libros, documentos, etc.)
- La estructura de recibos, que es algo entre forma tabular y forma libre, es difícil de manejar para cualquier motor de diseño.
Tu mejor apuesta es realizar lo siguiente:
- Analizar las imágenes de entrada. Si son difíciles de leer por los ojos, también son difíciles de leer para corregir el efecto.
- Realizar preprocesamiento adicional de imágenes. El escalado de imagen (0.5x, 1.5x, 2x) a veces ayuda mucho. Limpiar el ruido existente también ayuda.
- Entrenamiento de tesseract. No es tan difícil de hacer :)
- Resultado del procesamiento posterior de OCR para asegurar el diseño.
La disposición se realiza mejor mediante el análisis de la geometría de los resultados, no mediante expresiones regulares. Las expresiones regulares tienen problemas si el OCR tiene errores. Al usar la geometría, por ejemplo, encuentra un buen candidato para el número de UPC, dibuje una línea a través de los centros de los caracteres y luego sepa exactamente qué precio pertenece a esa UPC.
Además, algunas soluciones comerciales tienen personalizaciones para el escaneo de recibos, e incluso pueden ejecutarse muy rápido en dispositivos móviles.
La compañía con la que estoy trabajando, MicroBlink , tiene un módulo OCR para dispositivos móviles. Si estás en iOS, puedes probarlo fácilmente usando CocoaPods
pod try PPBlinkOCR
Terminé tirando esto completamente y estoy muy feliz con los resultados, así que pensé en publicarlo en caso de que alguien más lo encuentre útil.
No tuve que hacer ninguna división de imágenes y, en cambio, utilicé una expresión regular ya que los recibos de Wal-mart son muy predecibles.
Estoy en Windows, así que creé un script de powershell para ejecutar los comandos de conversión y encontrar y reemplazar expresiones regulares:
# -----------------------------------------------------------------
# Script: ParseReceipt.ps1
# Author: Jim Sanders
# Date: 7/27/2015
# Keywords: tesseract OCR ImageMagick CSV
# Comments:
# Used to convert a Wal-mart receipt image to a CSV file
# -----------------------------------------------------------------
param(
[Parameter(Mandatory=$true)] [string]$image
) # end param
# create output and temporary files based on input name
$base = (Get-ChildItem -Filter $image -File).BaseName
$csvOutfile = $base + ".txt"
$upscaleImage = $base + "_150.png"
$ocrFile = $base + "_ocr"
# upscale by 150% to ensure OCR works consistently
convert $image -resize 150% $upscaleImage
# perform the OCR to a temporary file
tesseract $upscaleImage -psm 6 $ocrFile
# column headers for the CSV
$newline = "Description,UPC,Type,Cost,TaxType`n"
$newline | Out-File $csvOutfile
# read in the OCR file and write back out the CSV (Tesseract automatically adds .txt to the file name)
$lines = Get-Content "$ocrFile.txt"
Foreach ($line in $lines) {
# This wraps the 12 digit UPC code and the price with commas, giving us our 5 columns for CSV
$newline = $line -replace ''/s/d{12}/s'','',$&,'' -replace ''./d+/./d{2}.'','',$&,'' -replace '',/s'','','' -replace ''/s,'','',''
$newline | Out-File -Append $csvOutfile
}
# clean up temporary files
del $upscaleImage
del "$ocrFile.txt"
El archivo resultante debe abrirse en Excel y luego ejecutar la función de texto a columnas para que no arruine los códigos UPC al convertirlos automáticamente en números. Este es un problema bien conocido en el que no me sumergiré, pero hay muchas formas de manejar y me decidí por esta forma un poco más manual.
Hubiera sido más feliz terminar con un simple .csv. Podía hacer doble clic pero no podía encontrar una buena manera de hacerlo sin dañar los códigos UPC aún más como si los envolviera en este formato:
"=""12345"""
Eso funciona, pero quería que el código UPC fuera solo los dígitos como texto en Excel, en caso de que fuera capaz de realizar una búsqueda en la API de Wal-Mart.
De todos modos, aquí está cómo se ven después de la importación y un formateo rápido:
https://s3.postimg.cc/b6cjsb4bn/Receipt_Excel.png
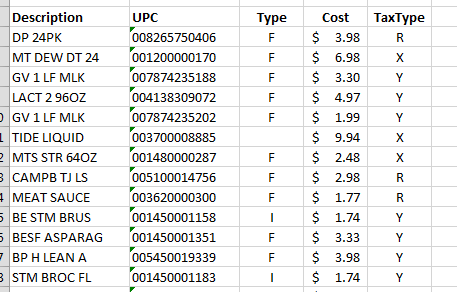{kind=link}
Todavía necesito hacer un poco de limpieza de basura en las filas que no son elementos de línea, pero todo eso solo toma unos segundos, así que no me molesta demasiado.
Gracias por el empujón en la dirección correcta @RevJohn, ¡no habría pensado en intentar simplemente escalar la imagen, pero eso hizo toda la diferencia en el mundo con Tesseract!