tutorial - Reordenar los elementos de la matriz para reflejar el agrupamiento de columnas y filas en Python naiive
seleccionar columnas en pandas (3)
Estoy buscando una manera de realizar el agrupamiento en clústeres por separado en las filas de la matriz y que en sus columnas, reordenar los datos en la matriz para reflejar el agrupamiento y juntarlos todos. El problema de la agrupación en clústeres se puede resolver fácilmente, al igual que la creación del dendrograma (por ejemplo, en este blog o en "Programación de inteligencia colectiva" ). Sin embargo, no queda claro cómo reordenar los datos.
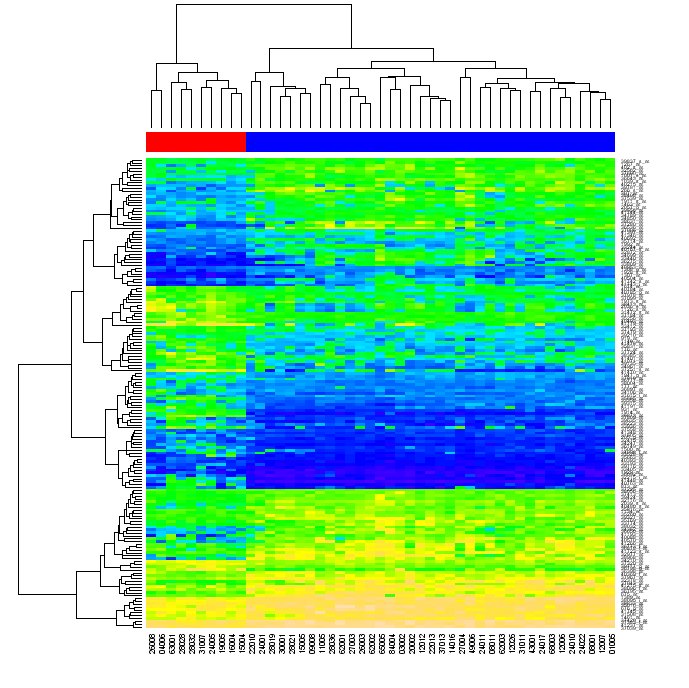
Eventualmente, estoy buscando una forma de crear gráficos similares a los de abajo usando Python ingenuo (con cualquier biblioteca "estándar" como numpy, matplotlib, etc., pero sin usar R u otras herramientas externas).
{kind=link}
Aclaraciones
Me preguntaron qué quería decir con reordenar. Cuando agrupa los datos en una matriz primero por filas de matriz, luego por sus columnas, cada celda de matriz puede identificarse por la posición en los dos dendrogramas. Si reordena las filas y las columnas de la matriz original de manera que los elementos que están cerca entre sí en los dendrogramas se aproximen entre sí en la matriz y luego generen un mapa de calor, la agrupación de los datos puede ser evidente para el espectador. (como en la figura de arriba)
No estoy seguro de entenderlo por completo, pero parece que está intentando volver a indexar cada eje de la matriz en función de los tipos de indicaciones del dendrograma. Supongo que eso supone que hay alguna lógica comparativa en cada delineación de la rama. Si este es el caso, entonces esto funcionaría (?):
>>> x_idxs = [(0,1,0,0),(0,1,1,1),(0,1,1),(0,0,1),(1,1,1,1),(0,0,0,0)]
>>> y_idxs = [(1,1),(0,1),(1,0),(0,0)]
>>> a = np.random.random((len(x_idxs),len(y_idxs)))
>>> x_idxs2, xi = zip(*sorted(zip(x_idxs,range(len(x_idxs)))))
>>> y_idxs2, yi = zip(*sorted(zip(y_idxs,range(len(y_idxs)))))
>>> a2 = a[xi,:][:,yi]
x_idxs y y_idxs son las indicaciones del dendrograma. a es la matriz sin clasificar. xi y yi son sus nuevas indicaciones de matriz de fila / columna. a2 es la matriz ordenada, mientras que x_idxs2 y y_idxs2 son las nuevas indicaciones de dendrogramas ordenadas. Esto supone que cuando se creó el dendrograma, una columna / fila de rama 0 siempre es comparativamente más grande / pequeña que una rama 1 .
Si su y_idxs y x_idxs no son listas pero son matrices numpy, entonces podría usar np.argsort de una manera similar.
Sé que esto es muy tarde para el juego, pero hice un objeto de trazado basado en el código de la publicación en esta página. Está registrado en pip, así que para instalarlo solo tienes que llamar
pip install pydendroheatmap
mira la página de github del proyecto aquí: https://github.com/themantalope/pydendroheatmap
Vea mi respuesta reciente , copiada en parte a continuación, a esta pregunta relacionada .
import scipy
import pylab
import scipy.cluster.hierarchy as sch
# Generate features and distance matrix.
x = scipy.rand(40)
D = scipy.zeros([40,40])
for i in range(40):
for j in range(40):
D[i,j] = abs(x[i] - x[j])
# Compute and plot dendrogram.
fig = pylab.figure()
axdendro = fig.add_axes([0.09,0.1,0.2,0.8])
Y = sch.linkage(D, method=''centroid'')
Z = sch.dendrogram(Y, orientation=''right'')
axdendro.set_xticks([])
axdendro.set_yticks([])
# Plot distance matrix.
axmatrix = fig.add_axes([0.3,0.1,0.6,0.8])
index = Z[''leaves'']
D = D[index,:]
D = D[:,index]
im = axmatrix.matshow(D, aspect=''auto'', origin=''lower'')
axmatrix.set_xticks([])
axmatrix.set_yticks([])
# Plot colorbar.
axcolor = fig.add_axes([0.91,0.1,0.02,0.8])
pylab.colorbar(im, cax=axcolor)
# Display and save figure.
fig.show()
fig.savefig(''dendrogram.png'')
Dendrograma y matriz de distancia http://up.stevetjoa.com/dendrogram.png
{kind=link}