remove - git tag best practices
¿Qué cometido tiene este blob? (8)
Dado el hash de un blob, ¿hay alguna manera de obtener una lista de confirmaciones que tengan este blob en su árbol?
Con Git 2.16 (Q1 2018), git describe sería una buena solución, ya que se le enseñó a cavar árboles más profundos para encontrar un <commit-ish>:<path> que se refiera a un objeto blob dado.
Consulte commit 644eb60 , commit 4dbc59a , commit cdaed0c , commit c87b653 , commit ce5b6f9 (16 Nov 2017) y commit 91904f5 , commit 2deda00 (02 Nov 2017) por Stefan Beller ( stefanbeller ) .
(Fusionada por Junio C Hamano - gitster - in commit 556de1a , 28 de diciembre de 2017)
builtin/describe.c: describe una burbujaA veces los usuarios reciben un hash de un objeto y quieren identificarlo más a fondo (por ejemplo: Use
verify-packpara encontrar los blobs más grandes, pero ¿qué son estos? O esta misma pregunta " ¿Qué cometido tiene este blob? ")Cuando describimos commits, tratamos de anclarlos a etiquetas o refs, ya que estos están conceptualmente en un nivel más alto que el commit. Y si no hay una referencia o etiqueta que coincida exactamente, no tenemos suerte.
Entonces, empleamos una heurística para crear un nombre para la confirmación. Estos nombres son ambiguos, puede haber diferentes etiquetas o refs para anclar, y puede haber una ruta diferente en el DAG para viajar para llegar al compromiso de forma precisa.Al describir un blob, también queremos describir el blob de una capa más alta, que es una tupla de
(commit, deep/path)ya que los objetos del árbol involucrados son bastante poco interesantes.
El mismo blob puede ser referenciado por múltiples commits, entonces, ¿cómo decidimos qué commit usar?Este parche implementa un enfoque bastante ingenuo sobre esto: ya que no hay indicadores de retroceso desde blobs a confirmaciones en las que se produce el blob, comenzaremos a caminar desde cualquier consejo disponible, enumerando los blobs en orden de la confirmación y una vez que encontramos el blob, tomaremos el primer commit que enlista el blob.
Por ejemplo:
git describe --tags v0.99:Makefile conversion-901-g7672db20c2:Makefilenos dice que el
Makefilecomo estaba env0.99se introdujo en commit 7672db2 .La caminata se realiza en orden inverso para mostrar la introducción de un blob en lugar de su última aparición.
Eso significa que la página de manual de git describe se agrega a los propósitos de este comando:
En lugar de simplemente describir una confirmación usando la etiqueta más reciente accesible desde allí, git describe dará a un objeto un nombre humano legible basado en una referencia disponible cuando se usa como git describe <blob> .
Si el objeto dado se refiere a un blob, se describirá como
<commit-ish>:<path>, de modo que el blob se encuentre en<path>en el<commit-ish>, que a su vez describe el primer commit en que este blob se produce en una caminata de revisión inversa desde HEAD.
Pero:
LOCO
Los objetos de árbol, así como los objetos de etiqueta que no apuntan a las confirmaciones, no se pueden describir .
Cuando se describen blobs, las etiquetas livianas que apuntan a blobs se ignoran, pero el blob aún se describe como<committ-ish>:<path>pesar de que la etiqueta liviana es favorable.
Dado el hash de un blob, ¿hay alguna manera de obtener una lista de confirmaciones que tengan este blob en su árbol?
Además de git describe , que mencioné en mi respuesta anterior , git log y git diff ahora se benefician también de la --find-object=<object-id> " --find-object=<object-id> " para limitar los hallazgos a los cambios que involucran el objeto nombrado .
Eso está en Git 2.16.x / 2.17 (Q1 2018)
Ver commit 4d8c51a , commit 5e50525 , commit 15af58c , commit cf63051 , commit c1ddc46 , commit 929ed70 (04 ene 2018) por Stefan Beller ( stefanbeller ) .
(Fusionado por Junio C Hamano - gitster - in commit c0d75f0 , 23 de enero de 2018)
diffcore: agrega una opción de pico para encontrar un blob específicoA veces los usuarios reciben un hash de un objeto y quieren identificarlo más a fondo (por ejemplo: Use verify-pack para encontrar los blobs más grandes, pero ¿cuáles son estos? O esta pregunta de desbordamiento de pila " ¿Qué cometido tiene este blob? ")
Uno podría tener la tentación de extender
git-describepara que también funcione con blobs, de modo quegit describe <blob-id>da una descripción como '':''.
Esto fue implementado aquí ; como se ve por el gran número de respuestas (> 110), resulta complicado hacer las cosas bien.
La parte difícil para hacerlo bien es escoger el ''commit-ish'' correcto, ya que podría ser la confirmación que (re) introdujo el blob o el blob que eliminó el blob; la burbuja podría existir en diferentes ramas.Junio sugirió un enfoque diferente para resolver este problema, que implementa este parche.
Enseñe a la maquinaria dediffotra bandera para restringir la información a lo que se muestra.
Por ejemplo:
$ ./git log --oneline --find-object=v2.0.0:Makefile b2feb64 Revert the whole "ask curl-config" topic for now 47fbfde i18n: only extract comments marked with "TRANSLATORS:"observamos que el
v1.9.2-471-g47fbfded53enviado con2.0apareció env1.9.2-471-g47fbfded53y env2.0.0-rc1-5-gb2feb6430b.
La razón por la cual estos commits ocurren antes de v2.0.0 son combinaciones malignas que no se encuentran usando este nuevo mecanismo.
Entonces ... Necesitaba encontrar todos los archivos por encima de un límite determinado en un repositorio de más de 8GB de tamaño, con más de 108,000 revisiones. Adapte el script de perl de Aristóteles junto con un script de rubí que escribí para llegar a esta solución completa.
En primer lugar, git gc : haga esto para asegurarse de que todos los objetos se encuentren en archivos de paquete; no escaneamos objetos que no estén en los archivos del paquete.
Siguiente Ejecute este script para ubicar todos los blobs en CUTOFF_SIZE bytes. Capture la salida en un archivo como "large-blobs.log"
#!/usr/bin/env ruby
require ''log4r''
# The output of git verify-pack -v is:
# SHA1 type size size-in-packfile offset-in-packfile depth base-SHA1
#
#
GIT_PACKS_RELATIVE_PATH=File.join(''.git'', ''objects'', ''pack'', ''*.pack'')
# 10MB cutoff
CUTOFF_SIZE=1024*1024*10
#CUTOFF_SIZE=1024
begin
include Log4r
log = Logger.new ''git-find-large-objects''
log.level = INFO
log.outputters = Outputter.stdout
git_dir = %x[ git rev-parse --show-toplevel ].chomp
if git_dir.empty?
log.fatal "ERROR: must be run in a git repository"
exit 1
end
log.debug "Git Dir: ''#{git_dir}''"
pack_files = Dir[File.join(git_dir, GIT_PACKS_RELATIVE_PATH)]
log.debug "Git Packs: #{pack_files.to_s}"
# For details on this IO, see http://.com/questions/1154846/continuously-read-from-stdout-of-external-process-in-ruby
#
# Short version is, git verify-pack flushes buffers only on line endings, so
# this works, if it didn''t, then we could get partial lines and be sad.
types = {
:blob => 1,
:tree => 1,
:commit => 1,
}
total_count = 0
counted_objects = 0
large_objects = []
IO.popen("git verify-pack -v -- #{pack_files.join(" ")}") do |pipe|
pipe.each do |line|
# The output of git verify-pack -v is:
# SHA1 type size size-in-packfile offset-in-packfile depth base-SHA1
data = line.chomp.split('' '')
# types are blob, tree, or commit
# we ignore other lines by looking for that
next unless types[data[1].to_sym] == 1
log.info "INPUT_THREAD: Processing object #{data[0]} type #{data[1]} size #{data[2]}"
hash = {
:sha1 => data[0],
:type => data[1],
:size => data[2].to_i,
}
total_count += hash[:size]
counted_objects += 1
if hash[:size] > CUTOFF_SIZE
large_objects.push hash
end
end
end
log.info "Input complete"
log.info "Counted #{counted_objects} totalling #{total_count} bytes."
log.info "Sorting"
large_objects.sort! { |a,b| b[:size] <=> a[:size] }
log.info "Sorting complete"
large_objects.each do |obj|
log.info "#{obj[:sha1]} #{obj[:type]} #{obj[:size]}"
end
exit 0
end
A continuación, edite el archivo para eliminar cualquier blobs que no espere y los bits INPUT_THREAD en la parte superior. una vez que tenga solo líneas para los sha1s que desea encontrar, ejecute el siguiente script de esta manera:
cat edited-large-files.log | cut -d'' '' -f4 | xargs git-find-blob | tee large-file-paths.log
Donde el script git-find-blob está debajo.
#!/usr/bin/perl
# taken from: http://.com/questions/223678/which-commit-has-this-blob
# and modified by Carl Myers <[email protected]> to scan multiple blobs at once
# Also, modified to keep the discovered filenames
# vi: ft=perl
use 5.008;
use strict;
use Memoize;
use Data::Dumper;
my $BLOBS = {};
MAIN: {
memoize ''check_tree'';
die "usage: git-find-blob <blob1> <blob2> ... -- [<git-log arguments ...>]/n"
if not @ARGV;
while ( @ARGV && $ARGV[0] ne ''--'' ) {
my $arg = $ARGV[0];
#print "Processing argument $arg/n";
open my $rev_parse, ''-|'', git => ''rev-parse'' => ''--verify'', $arg or die "Couldn''t open pipe to git-rev-parse: $!/n";
my $obj_name = <$rev_parse>;
close $rev_parse or die "Couldn''t expand passed blob./n";
chomp $obj_name;
#$obj_name eq $ARGV[0] or print "($ARGV[0] expands to $obj_name)/n";
print "($arg expands to $obj_name)/n";
$BLOBS->{$obj_name} = $arg;
shift @ARGV;
}
shift @ARGV; # drop the -- if present
#print "BLOBS: " . Dumper($BLOBS) . "/n";
foreach my $blob ( keys %{$BLOBS} ) {
#print "Printing results for blob $blob:/n";
open my $log, ''-|'', git => log => @ARGV, ''--pretty=format:%T %h %s''
or die "Couldn''t open pipe to git-log: $!/n";
while ( <$log> ) {
chomp;
my ( $tree, $commit, $subject ) = split " ", $_, 3;
#print "Checking tree $tree/n";
my $results = check_tree( $tree );
#print "RESULTS: " . Dumper($results);
if (%{$results}) {
print "$commit $subject/n";
foreach my $blob ( keys %{$results} ) {
print "/t" . (join ", ", @{$results->{$blob}}) . "/n";
}
}
}
}
}
sub check_tree {
my ( $tree ) = @_;
#print "Calculating hits for tree $tree/n";
my @subtree;
# results = { BLOB => [ FILENAME1 ] }
my $results = {};
{
open my $ls_tree, ''-|'', git => ''ls-tree'' => $tree
or die "Couldn''t open pipe to git-ls-tree: $!/n";
# example git ls-tree output:
# 100644 blob 15d408e386400ee58e8695417fbe0f858f3ed424 filaname.txt
while ( <$ls_tree> ) {
//A[0-7]{6} (/S+) (/S+)/s+(.*)/
or die "unexpected git-ls-tree output";
#print "Scanning line ''$_'' tree $2 file $3/n";
foreach my $blob ( keys %{$BLOBS} ) {
if ( $2 eq $blob ) {
print "Found $blob in $tree:$3/n";
push @{$results->{$blob}}, $3;
}
}
push @subtree, [$2, $3] if $1 eq ''tree'';
}
}
foreach my $st ( @subtree ) {
# $st->[0] is tree, $st->[1] is dirname
my $st_result = check_tree( $st->[0] );
foreach my $blob ( keys %{$st_result} ) {
foreach my $filename ( @{$st_result->{$blob}} ) {
my $path = $st->[1] . ''/'' . $filename;
#print "Generating subdir path $path/n";
push @{$results->{$blob}}, $path;
}
}
}
#print "Returning results for tree $tree: " . Dumper($results) . "/n/n";
return $results;
}
La salida se verá así:
<hash prefix> <oneline log message>
path/to/file.txt
path/to/file2.txt
...
<hash prefix2> <oneline log msg...>
Y así. Se enumerará cada confirmación que contenga un archivo grande en su árbol. si grep las líneas que comienzan con una pestaña y uniq eso, tendrá una lista de todas las rutas que puede filtrar-branch para eliminar, o puede hacer algo más complicado.
Permítanme reiterar: este proceso se ejecutó con éxito, en un repositorio de 10 GB con 108,000 confirmaciones. Tomó mucho más tiempo de lo que predije cuando corría en una gran cantidad de blobs, sin embargo, durante 10 horas, tendré que ver si el bit de memorización está funcionando ...
Estos son los detalles de un guión que pulí como la respuesta a una pregunta similar , y aquí puedes verlo en acción:
La captura de pantalla de git-ls-dir se ejecuta en http://adamspiers.org/computing/git-ls-dir.png
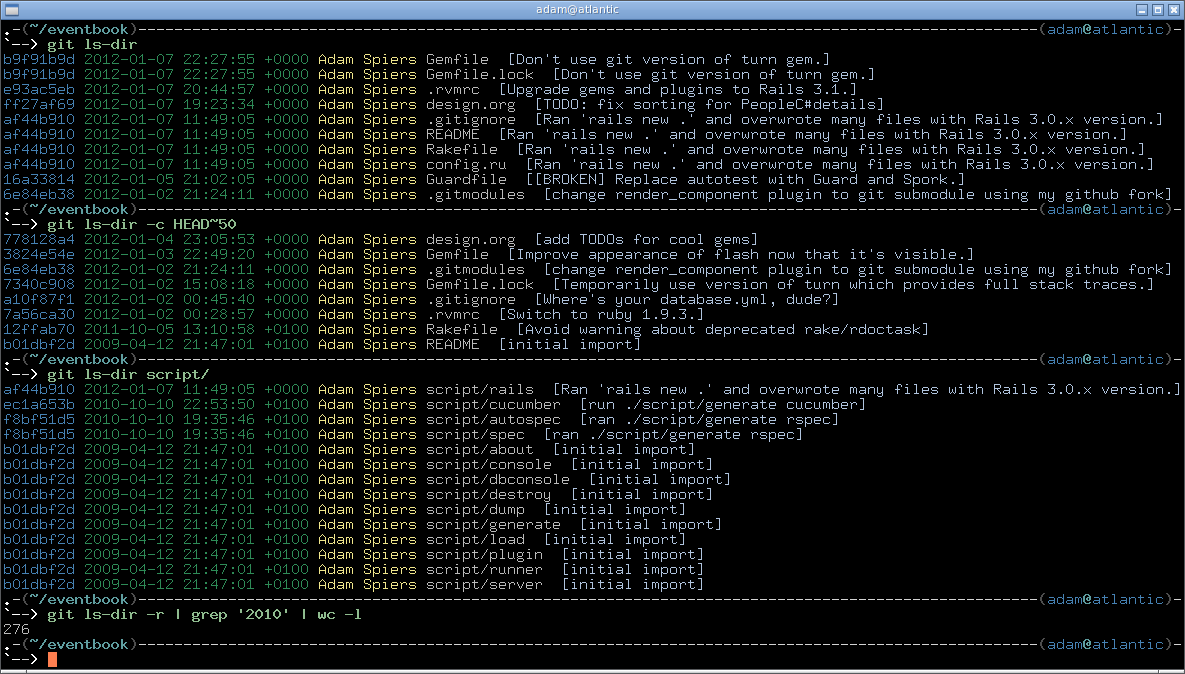{kind=link}
Lamentablemente, las secuencias de comandos fueron un poco lentas para mí, así que tuve que optimizar un poco. Afortunadamente, no solo tenía el hash sino también la ruta de un archivo.
git log --all --pretty=format:%H <path> | xargs -n1 -I% sh -c "git ls-tree % <path> | grep -q <hash> && echo %"
Los dos scripts siguientes toman el SHA1 del blob como primer argumento, y después de éste, opcionalmente, cualquier argumento que git log comprenda. Por ejemplo: todo para buscar en todas las ramas en lugar de solo en la actual, o -g para buscar en el reflog, o cualquier otra cosa que te apetezca.
Aquí está como un guión de shell: corto y dulce, pero lento:
#!/bin/sh
obj_name="$1"
shift
git log "$@" --pretty=format:''%T %h %s'' /
| while read tree commit subject ; do
if git ls-tree -r $tree | grep -q "$obj_name" ; then
echo $commit "$subject"
fi
done
Y una versión optimizada en Perl, aún bastante corta pero mucho más rápida:
#!/usr/bin/perl
use 5.008;
use strict;
use Memoize;
my $obj_name;
sub check_tree {
my ( $tree ) = @_;
my @subtree;
{
open my $ls_tree, ''-|'', git => ''ls-tree'' => $tree
or die "Couldn''t open pipe to git-ls-tree: $!/n";
while ( <$ls_tree> ) {
//A[0-7]{6} (/S+) (/S+)/
or die "unexpected git-ls-tree output";
return 1 if $2 eq $obj_name;
push @subtree, $2 if $1 eq ''tree'';
}
}
check_tree( $_ ) && return 1 for @subtree;
return;
}
memoize ''check_tree'';
die "usage: git-find-blob <blob> [<git-log arguments ...>]/n"
if not @ARGV;
my $obj_short = shift @ARGV;
$obj_name = do {
local $ENV{''OBJ_NAME''} = $obj_short;
`git rev-parse --verify /$OBJ_NAME`;
} or die "Couldn''t parse $obj_short: $!/n";
chomp $obj_name;
open my $log, ''-|'', git => log => @ARGV, ''--pretty=format:%T %h %s''
or die "Couldn''t open pipe to git-log: $!/n";
while ( <$log> ) {
chomp;
my ( $tree, $commit, $subject ) = split " ", $_, 3;
print "$commit $subject/n" if check_tree( $tree );
}
Pensé que esto sería generalmente útil, así que escribí un pequeño script de perl para hacerlo:
#!/usr/bin/perl -w
use strict;
my @commits;
my %trees;
my $blob;
sub blob_in_tree {
my $tree = $_[0];
if (defined $trees{$tree}) {
return $trees{$tree};
}
my $r = 0;
open(my $f, "git cat-file -p $tree|") or die $!;
while (<$f>) {
if (/^/d+ blob (/w+)/ && $1 eq $blob) {
$r = 1;
} elsif (/^/d+ tree (/w+)/) {
$r = blob_in_tree($1);
}
last if $r;
}
close($f);
$trees{$tree} = $r;
return $r;
}
sub handle_commit {
my $commit = $_[0];
open(my $f, "git cat-file commit $commit|") or die $!;
my $tree = <$f>;
die unless $tree =~ /^tree (/w+)$/;
if (blob_in_tree($1)) {
print "$commit/n";
}
while (1) {
my $parent = <$f>;
last unless $parent =~ /^parent (/w+)$/;
push @commits, $1;
}
close($f);
}
if (!@ARGV) {
print STDERR "Usage: git-find-blob blob [head ...]/n";
exit 1;
}
$blob = $ARGV[0];
if (@ARGV > 1) {
foreach (@ARGV) {
handle_commit($_);
}
} else {
handle_commit("HEAD");
}
while (@commits) {
handle_commit(pop @commits);
}
Pondré esto en Github cuando llegue a casa esta noche.
Actualización: Parece que alguien ya hizo esto . Ese usa la misma idea general pero los detalles son diferentes y la implementación es mucho más corta. No sé cuál sería más rápido, pero el rendimiento probablemente no sea una preocupación aquí.
Actualización 2: Por lo que vale, mi implementación es mucho más rápida, especialmente para un gran repositorio. Ese git ls-tree -r realmente duele.
Actualización 3: debo señalar que mis comentarios de rendimiento anteriores se aplican a la implementación que he vinculado anteriormente en la primera Actualización. La implementación de Aristóteles funciona de manera comparable a la mía. Más detalles en los comentarios para aquellos que son curiosos.
Si bien la pregunta original no lo pide, creo que es útil también verificar el área de ensayo para ver si se hace referencia a un blob. Modifiqué el script bash original para hacer esto y encontré lo que hacía referencia a un blob corrupto en mi repositorio:
#!/bin/sh
obj_name="$1"
shift
git ls-files --stage /
| if grep -q "$obj_name"; then
echo Found in staging area. Run git ls-files --stage to see.
fi
git log "$@" --pretty=format:''%T %h %s'' /
| while read tree commit subject ; do
if git ls-tree -r $tree | grep -q "$obj_name" ; then
echo $commit "$subject"
fi
done