video - transformada discreta del coseno imagenes
Compresión de video: ¿Qué es la transformación discreta de coseno? (6)
Si mal no recuerdo, esta matriz le permite guardar los datos en un archivo con compresión.
Si lee más abajo, encontrará el patrón en zig-zag de datos para leer desde esa matriz final. Los datos más importantes se encuentran en la esquina superior izquierda, y los menos importantes en la esquina inferior derecha. Como tal, si deja de escribir en algún momento y considera el resto como 0, aunque no lo sean, obtendrá una aproximación con pérdida de la imagen.
La cantidad de valores que tiras aumenta la compresión a costa de la fidelidad de la imagen.
Pero estoy seguro de que alguien más puede darte una mejor explicación.
Implementé una técnica de transformación de imagen / video llamada transformación discreta del coseno. Esta técnica se usa en la codificación de video MPEG. Basé mi algoritmo en las ideas presentadas en la siguiente URL:
http://vsr.informatik.tu-chemnitz.de/~jan/MPEG/HTML/mpeg_tech.html
Ahora puedo transformar una sección de 8x8 de una imagen en blanco y negro, como por ejemplo:
0140 0124 0124 0132 0130 0139 0102 0088 0140 0123 0126 0132 0134 0134 0088 0117 0143 0126 0126 0133 0134 0138 0081 0082 0148 0126 0128 0136 0137 0134 0079 0130 0147 0128 0126 0137 0138 0145 0132 0144 0147 0131 0123 0138 0137 0140 0145 0137 0142 0135 0122 0137 0140 0138 0143 0112 0140 0138 0125 0137 0140 0140 0148 0143
En esto una imagen con toda la información importante en la parte superior derecha. El bloque transformado se ve así:
1041 0039 -023 0044 0027 0000 0021 -019 -050 0044 -029 0000 0009 -014 0032 -010 0000 0000 0000 0000 -018 0010 -017 0000 0014 -019 0010 0000 0000 0016 -012 0000 0010 -010 0000 0000 0000 0000 0000 0000 -016 0021 -014 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 -010 0013 -014 0010 0000 0000
Ahora, necesito saber cómo puedo aprovechar esta transformación? Me gustaría detectar otros bloques de 8x8 en la misma imagen (u otra imagen) que representen una buena coincidencia.
Además, ¿qué me da esta transformación? ¿Por qué es importante la información almacenada en la esquina superior derecha de la imagen convertida?
El resultado de una DCT es una transformación de la fuente original en el dominio de la frecuencia. La entrada de la parte superior izquierda almacena la frecuencia y la frecuencia de "amplitud" aumenta a lo largo de los ejes horizontal y vertical. El resultado de la DCT suele ser una colección de amplitudes en las frecuencias más bajas más usuales (el cuadrante superior izquierdo) y menos entradas en las frecuencias más altas. Como mencionan lassevk, es habitual poner a cero estas frecuencias más altas ya que normalmente constituyen partes muy pequeñas de la fuente. Sin embargo, esto da como resultado la pérdida de información. Para completar la compresión, es habitual utilizar una compresión sin pérdida sobre la fuente DCT. Aquí es donde entra la compresión, ya que todas las carreras de ceros se empaquetan casi hasta la nada.
Una posible ventaja de usar el DCT para encontrar regiones similares es que puede hacer una coincidencia de primer paso en los valores de baja frecuencia (esquina superior izquierda). Esto reduce la cantidad de valores con los que debe coincidir. Si encuentra coincidencias de valores de baja frecuencia, puede aumentar para comparar las frecuencias más altas.
Espero que esto ayude
Recomiendo recoger una copia de la compresión de video digital : es una muy buena descripción general de los algoritmos de compresión para imágenes y video.
Aprendí todo lo que sé sobre el DCT de The Data Compression Book . Además de ser una excelente introducción al campo de la compresión de datos, tiene un capítulo cerca del final sobre la compresión de imágenes con pérdida que introduce JPEG y DCT.
La respuesta de Anthony Cramp me pareció bien. Como él menciona, DCT transforma los datos en el dominio de la frecuencia. El DCT se usa mucho en la compresión de video ya que el sistema visual humano debe ser menos sensible a los cambios de alta frecuencia, por lo que poner a cero los valores de frecuencia más altos resulta en un archivo más pequeño, con poco efecto en la percepción de la calidad del video.
En términos de usar el DCT para comparar imágenes, supongo que el único beneficio real es si reduces los datos de frecuencia más alta y, por lo tanto, tienes un conjunto más pequeño de datos para buscar / combinar. Algo como las ondas de Harr pueden dar mejores resultados de coincidencia de imágenes.
Los conceptos que subyacen a este tipo de transformaciones se ven más fácilmente al observar primero un caso unidimensional. La imagen aquí muestra una onda cuadrada junto con varios de los primeros términos de una serie infinita. Mirándolo, tenga en cuenta que si las funciones para los términos se suman, comienzan a aproximarse a la forma de la onda cuadrada. Cuantos más términos agregue, mejor será la aproximación. Pero, para obtener una aproximación a la señal exacta, debe sumar un número infinito de términos. La razón de esto es que la onda cuadrada es discontinua. Si piensas en una onda cuadrada como función del tiempo, va de -1 a 1 en tiempo cero. Para representar tal cosa se requiere una serie infinita. Eche otro vistazo a la trama de los términos de la serie. El primero es rojo, el segundo amarillo. Los términos sucesivos tienen más transiciones "hacia arriba y hacia abajo". Estos son de la creciente frecuencia de cada término. Siguiendo con la onda cuadrada como una función del tiempo, y cada término de la serie una función de frecuencia, hay dos representaciones equivalentes: una función de tiempo y una función de frecuencia (1 / tiempo).
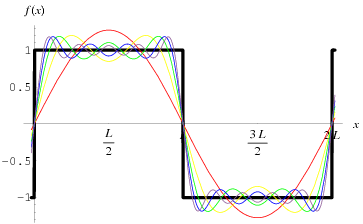{kind=link}
En el mundo real, no hay olas cuadradas. Nada sucede en el tiempo cero. Las señales de audio, por ejemplo, ocupan el rango de 20Hz a 20KHz, donde Hz es 1 / tiempo. Tales cosas se pueden representar con series finitas ''.
Para las imágenes, las matemáticas son las mismas, pero dos cosas son diferentes. Primero, es bidimensional. En segundo lugar, la noción de tiempo no tiene sentido. En el sentido 1D, la onda cuadrada es simplemente una función que da un valor numérico para un argumento que dijimos que era el tiempo. Una imagen (estática) es una función que proporciona un valor numérico para cada par de filas, indecisiones de columna. En otras palabras, la imagen es una función de un espacio 2D, que es una región rectangular. Una función como esa se puede representar en términos de su frecuencia espacial. Para entender qué frecuencia espacial es, considere una imagen de nivel de grises de 8 bits y un par de píxeles adyacentes. La transición más abrupta que puede ocurrir en la imagen va de 0 (digamos negro) a 255 (digamos blanco) sobre la distancia de 1 píxel. Esto corresponde directamente con el término de frecuencia más alta (último) de una representación en serie.
Una transformación bidimensional de Fourier (o Coseno) de la imagen da como resultado una matriz de valores del mismo tamaño que la imagen, que representa la misma información no como una función del espacio, sino como una función de 1 / espacio. La información se ordena de la frecuencia más baja a la más alta a lo largo de la diagonal desde el origen más alto de las filas y columnas. Un ejemplo está aquí .
{kind=link}
Para la compresión de imágenes, puede transformar una imagen, descartar algunos términos de mayor frecuencia y transformar los restantes a una imagen que tiene menos detalles que el original. Aunque se transforma de nuevo en una imagen del mismo tamaño (con los términos eliminados reemplazados por cero), en el dominio de la frecuencia ocupa menos espacio.
Otra forma de verlo es reducir una imagen a un tamaño más pequeño. Si, por ejemplo, intentas reducir el tamaño de una imagen tirando tres de cada cuatro píxeles en una fila, y tres de cada cuatro filas, tendrás una matriz 1/4 del tamaño pero la imagen se verá terrible. En la mayoría de los casos, esto se logra con un interpolador 2D, que produce nuevos píxeles promediando los grupos rectangulares de los píxeles de la imagen más grande. Al hacerlo, la interpolación tiene un efecto similar al tirar los términos de la serie en el dominio de la frecuencia, solo que es mucho más rápido de calcular.
Para hacer más cosas, voy a referirme a una transformación de Fourier como ejemplo. Cualquier buena discusión sobre el tema ilustrará cómo se relacionan las transformaciones de Fourier y Coseno. La transformación de Fourier de una imagen no se puede ver directamente como tal, porque está compuesta de números complejos. Ya está segregado en dos tipos de información, las partes real e imaginaria de los números. Por lo general, verá imágenes o tramas de estos. Pero es más significativo (generalmente) separar los números complejos en su magnitud y ángulo de fase. Esto es simplemente tomar un número complejo en el plano complejo y cambiar a coordenadas polares.
Para la señal de audio, piense en las funciones combinadas pecado y coseno tomando una cantidad attitional en sus argumentos para desplazar la función hacia adelante y hacia atrás (como parte de la representación de la señal). Para una imagen, la información de fase describe cómo cada término de la serie se desplaza con respecto a los otros términos en el espacio de frecuencia. En las imágenes, los bordes son (con suerte) tan distintos que están bien caracterizados por los términos de menor frecuencia en el dominio de la frecuencia. Esto no sucede porque son transiciones abruptas, sino porque tienen, por ejemplo, una gran cantidad de área negra adyacente a una gran cantidad de área más clara. Considere una porción unidimensional de un borde. El nivel de gris es cero, luego sube y se queda allí. Visualice la onda sinusoidal que sería el primer término de aproximación donde cruza el punto medio de la transición de la señal en sen (0). El ángulo de fase de este término corresponde a un desplazamiento en el espacio de la imagen. Un gran ejemplo de esto está disponible aquí . Si está tratando de encontrar formas y puede hacer una forma de referencia, esta es una forma de reconocerlas.