script - Bash, Linux: establece la diferencia entre dos archivos de texto
diferencia entre shell y bash (5)
Alguien me mostró cómo hacer exactamente esto hace un par de meses, y luego no pude encontrarlo por un tiempo ... y mientras miraba tropecé con tu pregunta. Aquí está :
set_union () {
sort $1 $2 | uniq
}
set_difference () {
sort $1 $2 $2 | uniq -u
}
set_symmetric_difference() {
sort $1 $2 | uniq -u
}
Tengo dos archivos A - nodes_to_delete y B - nodes_to_keep . Cada archivo tiene muchas líneas con identificadores numéricos.
Quiero tener la lista de identificadores numéricos que están en nodes_to_delete pero NO en nodes_to_keep , por ejemplo, alt text http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif .
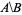{kind=link}
Hacerlo dentro de una base de datos PostgreSQL es irrazonablemente lento. ¿Alguna forma ordenada de hacerlo en bash usando las herramientas CLI de Linux?
ACTUALIZACIÓN: Esto parece ser un trabajo Pythonic, pero los archivos son realmente, muy grandes. He resuelto algunos problemas similares usando uniq , sort y algunas técnicas de teoría de conjuntos. Esto fue aproximadamente dos o tres órdenes de magnitud más rápido que los equivalentes de la base de datos.
El comando comm hace eso.
Tal vez necesites una mejor manera de hacerlo en Postgres, puedo apostar que no encontrarás una forma más rápida de hacerlo con archivos planos. Debería poder realizar una unión interna simple y asumir que ambos id cols están indexados, lo que debería ser muy rápido.
use comm - comparará dos archivos ordenados línea por línea
La respuesta a la pregunta de OP usando esta configuración de ejemplo aparece a continuación. Este comando devolverá líneas exclusivas para deleteNodes, no en keepNodes
comm -1 -3 <(sort keepNodes) <(sort deleteNodes)explicación: mostrar líneas únicas para deleteNodes, ocultar otras líneas
configuración de ejemplo
Usaremos keepNodes y deleteNodes. Se usan como entrada sin clasificar.
$ cat > keepNodes <(echo bob; echo amber;)
$ cat > deleteNodes <(echo bob; echo ann;)
Por defecto, sin argumentos, comm imprime 3 columnas
unique_to_FILE1
unique_to_FILE2
lines_appear_in_both
Este es un ejemplo básico de comm sin argumentos. Tenga en cuenta las tres columnas.
$ comm <(sort keepNodes) <(sort deleteNodes)
amber
ann
bob
Suprimir la salida de la columna
Suprima la columna 1, 2 o 3 con -N; tenga en cuenta que cuando una columna está oculta, el espacio en blanco se encoge.
$ comm -1 <(sort keepNodes) <(sort deleteNodes)
ann
bob
$ comm -2 <(sort keepNodes) <(sort deleteNodes)
amber
bob
$ comm -3 <(sort keepNodes) <(sort deleteNodes)
amber
ann
$ comm -1 -3 <(sort keepNodes) <(sort deleteNodes)
ann
$ comm -2 -3 <(sort keepNodes) <(sort deleteNodes)
amber
$ comm -1 -2 <(sort keepNodes) <(sort deleteNodes)
bob
Fallará con gracia cuando olvide clasificar
comm: file 1 is not in sorted order
comm fue diseñado específicamente para este tipo de caso de uso, pero requiere una entrada ordenada.
awk es posiblemente una mejor herramienta para esto, ya que es bastante sencillo encontrar la diferencia establecida, no requiere sort y ofrece flexibilidad adicional.
awk ''NR == FNR { a[$0]; next } !($0 in a)'' nodes_to_keep nodes_to_delete
Tal vez, por ejemplo, desee encontrar solo la diferencia en las líneas que representan números no negativos:
awk -v r=''^[0-9]+$'' ''NR == FNR && $0 ~ r {
a[$0]
next
} $0 ~ r && !($0 in a)'' nodes_to_keep nodes_to_delete