python - Aleatorio es apenas aleatorio en absoluto?
random birthday-paradox (11)
Hice esto para probar la aleatoriedad de randint:
>>> from random import randint
>>>
>>> uniques = []
>>> for i in range(4500): # You can see I was optimistic.
... x = randint(500, 5000)
... if x in uniques:
... raise Exception(''We duped %d at iteration number %d'' % (x, i))
... uniques.append(x)
...
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
Exception: We duped 887 at iteration number 7
Intenté unas 10 veces más y el mejor resultado que obtuve fueron 121 iteraciones antes de un repetidor. ¿Es este el mejor tipo de resultado que puede obtener de la biblioteca estándar?
La paradoja del cumpleaños, o por qué los PRNG producen duplicados con más frecuencia de lo que piensas.
Hay un par de problemas en juego en el problema del PO. Una es la paradoja del cumpleaños como se mencionó anteriormente y la segunda es la naturaleza de lo que está generando, lo que no garantiza inherentemente que un número dado no se repita.
La paradoja del cumpleaños se aplica donde el valor dado puede ocurrir más de una vez durante el período del generador y, por lo tanto, los duplicados pueden ocurrir dentro de una muestra de valores. El efecto de la paradoja del cumpleaños es que la probabilidad real de obtener esos duplicados es bastante significativa y el período promedio entre ellos es más pequeño de lo que uno hubiera pensado. Esta disonancia entre las probabilidades reales y percibidas hace que la paradoja del cumpleaños sea un buen ejemplo de un sesgo cognitivo , donde es probable que una estimación ingenua e intuitiva sea totalmente errónea.
Una guía rápida sobre Pseudo generadores de números aleatorios (PRNG)
La primera parte de su problema es que está tomando el valor expuesto de un generador de números aleatorios y convirtiéndolo en un número mucho más pequeño, por lo que se reduce el espacio de valores posibles. Aunque algunos generadores de números pseudoaleatorios no repiten valores durante su período, esta transformación cambia el dominio a uno mucho más pequeño. El dominio más pequeño invalida la condición "sin repeticiones", por lo que puede esperar una gran probabilidad de repetición.
Algunos algoritmos, como el PRNG congruente lineal ( A''=AX|M ) , garantizan la unicidad para todo el período. En un LCG, el valor generado contiene el estado completo del acumulador y no se guarda ningún estado adicional. El generador es determinista y no puede repetir un número dentro del período; cualquier valor de acumulador dado puede implicar solo un posible valor sucesivo. Por lo tanto, cada valor solo puede ocurrir una vez dentro del período del generador. Sin embargo, el período de dicho PRNG es relativamente pequeño (alrededor de 2 ^ 30 para implementaciones típicas del algoritmo LCG) y no puede ser mayor que el número de valores distintos.
No todos los algoritmos PRNG comparten esta característica; algunos pueden repetir un valor dado dentro del período. En el problema del OP, el algoritmo de Mersenne Twister (utilizado en el módulo random de Python) tiene un período muy largo, mucho más que 2 ^ 32. A diferencia de un PRNG lineal congruente, el resultado no es puramente una función del valor de salida anterior, ya que el acumulador contiene un estado adicional. Con una salida entera de 32 bits y un período de ~ 2 ^ 19937, no es posible que proporcione una garantía de este tipo.
El Mersenne Twister es un algoritmo popular para los PRNG porque tiene buenas propiedades estadísticas y geométricas y un período muy largo: características deseables para un PRNG utilizado en los modelos de simulación.
Las buenas propiedades estadísticas significan que los números generados por el algoritmo se distribuyen uniformemente sin números que tengan una probabilidad significativamente mayor de aparecer que otros. Las malas propiedades estadísticas pueden producir sesgos no deseados en los resultados.
Las buenas propiedades geométricas significan que los conjuntos de N números no se encuentran en un hiperplano en N espacio dimensional. Las propiedades geométricas deficientes pueden generar correlaciones falsas en un modelo de simulación y distorsionar los resultados.
Un período largo significa que puede generar una gran cantidad de números antes de que la secuencia se adapte al inicio. Si un modelo necesita una gran cantidad de iteraciones o debe ejecutarse desde varias semillas, entonces los 2 ^ 30 o más números discretos disponibles de una implementación típica de LCG pueden no ser suficientes. El algoritmo MT19337 tiene un período muy largo: 2 ^ 19337-1, o aproximadamente 10 ^ 5821. En comparación, el número total de átomos en el universo se estima en aproximadamente 10 ^ 80.
El entero de 32 bits producido por un PRNG MT19337 no puede representar suficientes valores discretos para evitar repetir durante un período tan largo. En este caso, es probable que se produzcan valores duplicados e inevitables con una muestra lo suficientemente grande.
La paradoja del cumpleaños en pocas palabras
Este problema se define originalmente como la probabilidad de que dos personas en la habitación compartan el mismo cumpleaños. El punto clave es que dos personas en la sala podrían compartir un cumpleaños. Las personas tienden a malinterpretar ingenuamente el problema como la probabilidad de que alguien en la habitación comparta un cumpleaños con un individuo específico, que es la fuente del sesgo cognitivo que a menudo hace que las personas subestimen la probabilidad. Esta es la suposición incorrecta: no hay ningún requisito para que el emparejamiento sea para un individuo específico y dos individuos podrían coincidir.
La probabilidad de que se produzca una coincidencia entre dos individuos es mucho mayor que la probabilidad de una coincidencia con un individuo específico, ya que la coincidencia no tiene que ser en una fecha específica. Por el contrario, solo tiene que encontrar dos personas que comparten el mismo cumpleaños. De este gráfico (que se puede encontrar en la página de wikipedia sobre el tema), podemos ver que solo necesitamos 23 personas en la sala para que haya un 50% de posibilidades de encontrar dos que coincidan de esta manera.
De la entrada de Wikipedia sobre el tema , podemos obtener un buen resumen. En el problema del OP tenemos 4,500 posibles ''cumpleaños'', en lugar de 365. Para un número dado de valores aleatorios generados (que equivalen a ''personas''), queremos saber la probabilidad de que aparezcan dos valores idénticos dentro de la secuencia.
Calculando el efecto probable de la paradoja del cumpleaños en el problema del PO
Para una secuencia de 100 números, tenemos (100 * 99) / 2 = 4950 pares de http://mathurl.com/yc4cdsr.png (consulte Comprensión del problema ) que podrían coincidir (es decir, el primero podría coincidir con el segundo, tercero, etc., el segundo podría coincidir con el tercero, el cuarto, etc., así que el número de combinaciones que potencialmente podrían coincidir es bastante más que 100.
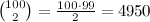{kind=link}
A partir del Cálculo de la Probabilidad obtenemos una expresión de 1 - (4500! / (4500 ** 100 * (4500 - 100)!) Http://mathurl.com/ybfweny.png . El siguiente fragmento de código de Python a continuación es ingenuo evaluación de la probabilidad de que se produzca un par coincidente.
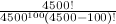{kind=link}
# === birthday.py ===========================================
#
from math import log10, factorial
PV=4500 # Number of possible values
SS=100 # Sample size
# These intermediate results are exceedingly large numbers;
# Python automatically starts using bignums behind the scenes.
#
numerator = factorial (PV)
denominator = (PV ** SS) * factorial (PV - SS)
# Now we need to get from bignums to floats without intermediate
# values too large to cast into a double. Taking the logs and
# subtracting them is equivalent to division.
#
log_prob_no_pair = log10 (numerator) - log10 (denominator)
# We''ve just calculated the log of the probability that *NO*
# two matching pairs occur in the sample. The probability
# of at least one collision is 1.0 - the probability that no
# matching pairs exist.
#
print 1.0 - (10 ** log_prob_no_pair)
Esto produce un resultado sensato de p = 0.669 para una coincidencia que ocurre dentro de los 100 números muestreados de una población de 4500 valores posibles. (Tal vez alguien podría verificar esto y publicar un comentario si está mal). De esto podemos ver que las longitudes de carreras entre los números coincidentes observados por el OP parecen ser bastante razonables.
Nota a pie de página: utilizar la mezcla para obtener una secuencia única de números pseudoaleatorios
Vea esta respuesta debajo de S. Mark para obtener un conjunto único garantizado de números aleatorios. La técnica a la que se refiere el póster toma una matriz de números (que usted suministra, por lo que puede hacerlos únicos) y los mezcla en orden aleatorio. Dibujar los números en secuencia desde la matriz mezclada le dará una secuencia de números pseudoaleatorios que se garantiza que no se repetirán.
Nota al pie: PRNG criptográficamente seguros
El algoritmo MT no es criptográficamente seguro ya que es relativamente fácil inferir el estado interno del generador al observar una secuencia de números. Otros algoritmos, como Blum Blum Shub, se usan para aplicaciones criptográficas, pero pueden ser inadecuados para aplicaciones de simulación o números aleatorios generales. Los PRNG criptográficamente seguros pueden ser costosos (quizás requiriendo cálculos bignum) o pueden no tener buenas propiedades geométricas. En el caso de este tipo de algoritmo, el requisito principal es que no sea computablemente factible inferir el estado interno del generador mediante la observación de una secuencia de valores.
Antes de echarle la culpa a Python, realmente debes repasar algunas teorías de probabilidad y estadística. Comience leyendo sobre la paradoja del cumpleaños
Por cierto, el módulo random en Python usa el Mersenne twister PRNG, que se considera muy bueno, tiene un período enorme y fue ampliamente probado. Así que puedes estar seguro de que estás en buenas manos.
Como respuesta a la respuesta de Nimbuz:
Eso no es un repetidor. Un repetidor es cuando repites la misma secuencia . No solo un número.
Está generando 4500 números aleatorios de un rango de 500 <= x <= 5000 . Luego verifica para ver si cada número se ha generado anteriormente. El problema del cumpleaños nos dice cuál es la probabilidad de que dos de esos números coincidan dado que n intenta salir de un rango d .
También puede invertir la fórmula para calcular cuántos números debe generar hasta que la posibilidad de generar un duplicado sea superior al 50% . En este caso, tienes >50% posibilidades de encontrar un número duplicado después de 79 iteraciones.
Existe la paradoja del cumpleaños. Teniendo esto en cuenta, te das cuenta de que lo que estás diciendo es que encontrar "764, 3875, 4290, 4378, 764" o algo así no es muy aleatorio porque un número en esa secuencia se repite. La verdadera forma de hacerlo es comparar secuencias entre sí. Escribí un script de Python para hacer esto.
from random import randint
y = 21533456
uniques = []
for i in range(y):
x1 = str(randint(500, 5000))
x2 = str(randint(500, 5000))
x3 = str(randint(500, 5000))
x4 = str(randint(500, 5000))
x = (x1 + ", " + x2 + ", " + x3 + ", " + x4)
if x in uniques:
raise Exception(''We duped the sequence %d at iteration number %d'' % (x, i))
else:
raise Exception(''Couldn/'t find a repeating sequence in %d iterations'' % (y))
uniques.append(x)
Ha definido un espacio aleatorio de 4501 valores (500-5000) y está iterando 4500 veces. Básicamente, se garantiza que obtendrá una colisión en la prueba que escribió.
Para pensar de otra manera:
- Cuando la matriz de resultados está vacía P (dupe) = 0
- 1 valor en Array P (dupe) = 1/4500
- 2 valores en Array P (dupe) = 2/4500
- etc.
Entonces, cuando llega a 45/4500, ese inserto tiene un 1% de posibilidades de ser un duplicado, y esa probabilidad sigue aumentando con cada inserto posterior.
Para crear una prueba que realmente pruebe las capacidades de la función aleatoria, aumente el universo de posibles valores aleatorios (p. Ej .: 500-500000) Puede o no obtener una estafa. Pero obtendrás muchas más iteraciones en promedio.
La aleatoriedad verdadera definitivamente incluye la repetición de valores antes de que se agote todo el conjunto de valores posibles. De lo contrario, no sería aleatorio, ya que sería capaz de predecir cuánto tiempo no se repetiría un valor.
Si alguna vez lanzaste dados, seguramente obtuviste 3 sixes seguidos con bastante frecuencia ...
La implementación aleatoria de Python es realmente muy avanzada:
Para cualquier otra persona con este problema, usé uuid.uuid4 () y funciona como un hechizo.
Si no quiere una repetitiva, genere una matriz secuencial y use random.shuffle