optimización - optimizar inner join sql server
¿Cómo puedo optimizar aún más una consulta de tabla derivada que funciona mejor que el equivalente JOINed? (4)
Acerca de BETWEEN
SELECT * FROM a WHERE a.column BETWEEN x AND y
- es indexable y corresponde a una búsqueda de rango en index a.column (si tiene uno)
- es 100% equivalente a
a.column >= x AND a.column <= y
Mientras esto:
SELECT * FROM a WHERE somevalue BETWEEN a.column1 AND a.column2
- es 100% equivalente a
somevalue >= a.column1 AND somevalue <= a.column2 - es una cosa muy diferente de la primera de arriba
- no es indexable por una búsqueda de rango (no hay rango, aquí tienes 2 columnas)
- generalmente conduce a un rendimiento de consulta horrible
Creo que hubo confusión sobre esto en el debate sobre "entre" arriba.
OP tiene el primer tipo, así que no te preocupes.
ACTUALIZACIÓN: Encontré una solución. Vea mi respuesta a continuación.
Mi pregunta
¿Cómo puedo optimizar esta consulta para minimizar mi tiempo de inactividad? Necesito actualizar más de 50 esquemas con la cantidad de tickets que van de 100,000 a 2 millones. ¿Es aconsejable intentar establecer todos los campos en tickets_extra al mismo tiempo? Siento que hay una solución aquí que simplemente no estoy viendo. He estado golpeando mi cabeza contra este problema por más de un día.
Además, inicialmente lo intenté sin utilizar un SELECTIVO secundario, pero el rendimiento fue mucho peor de lo que actualmente tengo.
Fondo
Estoy tratando de optimizar mi base de datos para un informe que debe ejecutarse. Los campos en los que necesito agregar son muy caros de calcular, así que estoy desnormalizando un poco mi esquema existente para adaptarlo a este informe. Tenga en cuenta que simplifiqué bastante la tabla de tickets al eliminar algunas docenas de columnas irrelevantes.
Mi informe agregará recuentos de boletos por el gerente cuando se creó y el administrador cuando se resuelva . Esta relación complicada está diagramada aquí:
EAV http://cdn.cloudfiles.mosso.com/c163801/eav.png
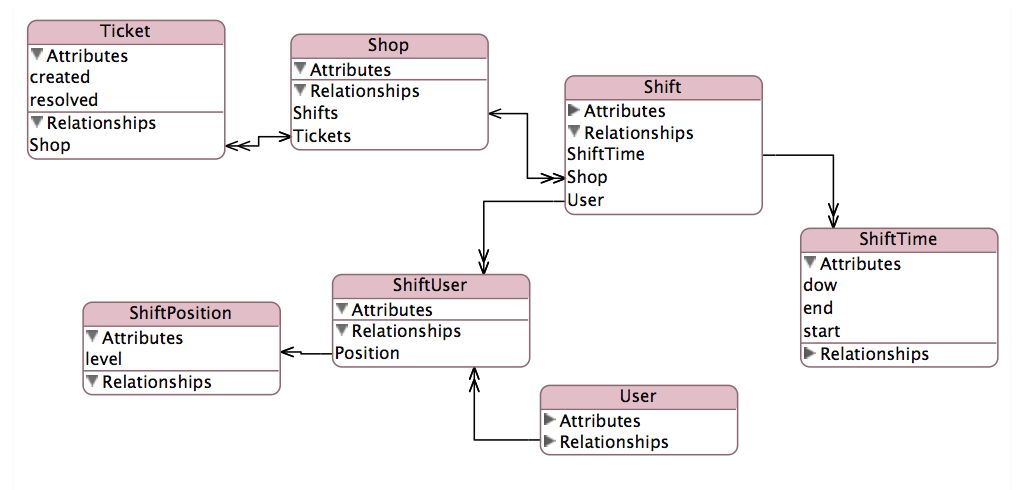{kind=link}
Para evitar la media docena de combinaciones desagradables requeridas para calcular esto sobre la marcha, he agregado la siguiente tabla a mi esquema:
mysql> show create table tickets_extra/G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
El problema ahora es que no he almacenado estos datos en ninguna parte. El gerente siempre se calculó dinámicamente. Tengo millones de tickets en varias bases de datos con el mismo esquema que necesita tener esta tabla poblada. Quiero hacer esto de la manera más eficiente posible, pero no he podido optimizar las consultas que estoy usando para hacerlo:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
Esta consulta toma más de una hora para ejecutarse en un esquema que tiene> 1.7 millones de tickets. Esto es inaceptable para la ventana de mantenimiento que tengo. Además, ni siquiera se encarga de calcular el campo manager_resolved, ya que intentar combinar eso en la misma consulta empuja el tiempo de consulta a la estratosfera. Mi inclinación actual es mantenerlos separados, y usar una ACTUALIZACIÓN para llenar el campo manager_resolved, pero no estoy seguro.
Finalmente, aquí está el resultado EXPLAIN de la porción SELECT de esa consulta:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
Muchas Gracias Por Leer!
Bueno, encontré una solución. Tomó mucha experimentación, y creo que un poco de suerte ciega, pero aquí está:
CREATE TABLE magic ENGINE=MEMORY
SELECT
s.shop_id AS shop_id,
s.id AS shift_id,
st.dow AS dow,
st.start AS start,
st.end AS end,
su.user_id AS manager_id
FROM shifts s
JOIN shift_times st ON s.id = st.shift_id
JOIN shifts_users su ON s.id = su.shift_id
JOIN shift_positions sp ON su.shift_position_id = sp.id AND sp.level = 1
ALTER TABLE magic ADD INDEX (shop_id, dow);
CREATE TABLE tickets_extra ENGINE=MyISAM
SELECT
t.id AS ticket_id,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.created) = m.dow
AND TIME(t.created) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_created,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.resolved) = m.dow
AND TIME(t.resolved) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_resolved
FROM tickets t;
DROP TABLE magic;
Larga explicación
Ahora, explicaré por qué esto funciona, y mi proceso relativo y pasos para llegar aquí.
Primero, sabía que la consulta que estaba tratando estaba sufriendo debido a la enorme tabla derivada, y las subsecuentes UNIONES a esto. Estaba tomando mi tabla de entradas bien indexadas y uniendo todos los datos de shift_times, y luego dejé que MySQL lo mordiera mientras intentaba unirse a los turnos y a la tabla shift_positions. Este behemoth derivado sería hasta 2 millones de fila desordenada fila.
Ahora, sabía que esto estaba pasando. Sin embargo, la razón por la que iba por este camino era porque la forma "adecuada" de hacer esto, utilizando estrictamente JOINs, tomaba una cantidad de tiempo aún mayor. Esto se debe al caos desagradable de caos requerido para determinar quién es el administrador de un turno determinado. Tengo que unirme a shift_times para descubrir cuál es el cambio correcto, y al mismo tiempo unirme a shift_positions para calcular el nivel del usuario. No creo que el optimizador de MySQL maneje esto muy bien, y termina creando una ENORME monstruosidad de una tabla temporal de las uniones, luego filtra lo que no aplica.
Entonces, como la tabla derivada parecía ser el "camino a seguir", insistí obstinadamente en esto por un tiempo. Intenté ponerlo en una cláusula JOIN, sin mejoría. Intenté crear una tabla temporal con la tabla derivada, pero nuevamente fue demasiado lenta ya que la tabla temporal no estaba indexada.
Me di cuenta de que tenía que manejar este cálculo de turno, tiempos, posiciones sanamente. Pensé, tal vez una VISTA sería el camino a seguir. ¿Qué ocurre si creo una VISTA que contiene esta información? (Shop_id, shift_id, dow, start, end, manager_id). Entonces, simplemente tendría que unirme a la tabla de tickets por shop_id y todo el cálculo de DAYOFWEEK / TIME, y estaría en el negocio. Por supuesto, no recuerdo que MySQL maneja VIEWs bastante bien. No se materializa en absoluto, simplemente ejecuta la consulta que habría utilizado para obtener la vista por usted. Así que uniendo tickets en esto, básicamente estaba ejecutando mi consulta original, sin mejoría.
Entonces, en lugar de una VISTA, decidí usar una TABLA TEMPORAL. Esto funcionó bien si solo obtenía uno de los administradores (creados o resueltos) a la vez, pero todavía era bastante lento. Además, descubrí que con MySQL no puede consultar la misma tabla dos veces en la misma consulta (tendría que unirme a mi tabla temporal dos veces para poder diferenciar entre manager_created y manager_resolved). Esta es una gran WTF, ya que puedo hacerlo siempre que no especifique "TEMPORARY" - aquí es donde entró en juego la magia CREATE TABLE ENGINE = MEMORY.
Con esta tabla pseudo temporal en la mano, probé mi JOIN para solo manager_created nuevamente. Funcionó bien, pero aún bastante lento. Sin embargo, cuando me UNIÉ de nuevo para obtener un manager_resolved en la misma consulta, el tiempo de consulta volvió a la estratosfera. Al mirar el EXPLAIN se mostró el escaneo completo de la tabla de tickets (filas ~ 2mln), como se esperaba, y los JOINs en la tabla mágica en ~ 2,087 cada uno. Una vez más, parecía estar tropezando con el fracaso.
Ahora comencé a pensar en cómo evitar las UNIONES por completo y fue entonces cuando encontré un oscuro mensaje de tablero antiguo donde alguien sugirió usar subselecciones (no puedo encontrar el enlace en mi historial). Esto es lo que llevó a la segunda consulta SELECT que se muestra arriba (la creación de tickets_extra uno). En el caso de seleccionar solo un campo de administrador, funcionó bien, pero nuevamente con ambos fue una mierda. Miré el EXPLAIN y vi esto:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 2. row ***************************
id: 3
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
3 rows in set (0.00 sec)
Ack, la temible SUBCONJUNÍA DEPENDIENTE. A menudo se sugiere evitar esto, ya que MySQL generalmente los ejecutará de manera externa, ejecutando la consulta interna para cada fila del exterior. Ignoré esto, y me pregunté: "Bueno ... ¿y si acabo de indexar esta estúpida mesa de magia?". Por lo tanto, nació el índice ADD (shop_id, dow).
Mira esto:
mysql> CREATE TABLE magic ENGINE=MEMORY
<snip>
Query OK, 3220 rows affected (0.40 sec)
mysql> ALTER TABLE magic ADD INDEX (shop_id, dow);
Query OK, 3220 rows affected (0.02 sec)
mysql> CREATE TABLE tickets_extra ENGINE=MyISAM
<snip>
Query OK, 1933769 rows affected (24.18 sec)
mysql> drop table magic;
Query OK, 0 rows affected (0.00 sec)
¡AHORA ESTO ES de lo que estoy hablando!
Conclusión
Esta es definitivamente la primera vez que he creado una tabla no TEMPORAL sobre la marcha, e INDEXed sobre la marcha, simplemente para hacer una sola consulta de manera eficiente. Supongo que siempre asumí que agregar un índice sobre la marcha es una operación prohibitivamente costosa. (Agregar un índice en mi tabla de tickets de 2mln filas puede tomar más de una hora). Sin embargo, por solo 3.000 filas, este es un juego de niños.
No tenga miedo de SUBCONJUNTAS DEPENDIENTES, creando tablas TEMPORALES que realmente no son, indexadas sobre la marcha o alienígenas. Todos pueden ser buenas cosas en la situación correcta.
Gracias por toda la ayuda de . :-RE
Deberías haber usado Postgres, lol. Una consulta simple como esta no debería tomar más de unas decenas de segundos, siempre que tengas suficiente memoria RAM para evitar agallas en el disco.
De todas formas.
=> ¿El problema está en SELECT o en INSERT?
(ejecuta el SELECT solo en un servidor de prueba y mide el tiempo).
=> ¿Está su disco de consulta vinculado o vinculado a la CPU?
Inicie en un servidor de prueba y verifique la salida de vmstat. Si está vinculado a la CPU, omita esto. Si está enlazado al disco, verifique el tamaño del conjunto de trabajo (es decir, el tamaño de su base de datos). Si el conjunto de trabajo es más pequeño que su RAM, no debe estar vinculado al disco. Puede forzar la carga de una tabla en el caché del sistema operativo antes de ejecutar una consulta iniciando una selección ficticia como SELECT suma (alguna columna) FROM table. Esto puede ser útil si una consulta selecciona muchas filas en orden aleatorio desde una tabla que no está almacenada en caché en la RAM ... activa una exploración secuencial de la tabla, que la carga en caché, y luego el acceso aleatorio es mucho más rápido. Con algunos trucos también puede almacenar índices en la memoria caché (o simplemente atacar el directorio de su base de datos a> / dev / null, lol).
Por supuesto, agregar más RAM podría ayudar (pero debe verificar si la consulta está matando primero el disco o la CPU). O decirle a MySQL que use más de su RAM en la configuración (key_buffer, etc.).
Si está ganando millones de copias de HDD aleatorias, está en DOLOR.
=> Aceptar ahora la consulta
PRIMERO, ANALIZA tus tablas.
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id WHERE shift_positions.level = 1
¿POR QUÉ DEJAS UNIRTE y luego agregar un DÓNDE? La IZQUIERDA no tiene sentido. Si no hay una fila en shift_positions, LEFT JOIN generará un NULL, y WHERE lo rechazará.
Solución: utilice JOIN en lugar de LEFT JOIN y mueva (nivel = 1) en la condición JOIN ON ().
Mientras estás en ello, también deshacerte de la otra LEFT JOIN (reemplaza por JOIN) a menos que realmente estés interesado en todos esos NULLs. (Supongo que no lo eres)
Ahora es probable que puedas deshacerte de la subselección.
Siguiente.
DONDE TIEMPO (t.created) ENTRE shift_times.start AND shift_times.end)
Esto no es indexable, porque tienes una función TIME () en la condición (usa Postgres, lol). Veamos:
JOIN shift_times ON (shift.id = shift_times.shift_id AND shift_times.dow = DAYOFWEEK (t.created) Y TIME (t.created) ENTRE shift_times.start AND shift_times.end)
Idealmente, le gustaría tener un índice de columnas múltiples en shift_times (shift_id, DAYOFWEEK (t.created), TIME (t.created)) para que este JOIN pueda indexarse.
Solución: agregue las columnas ''día'', ''hora'' a shift_times, que contengan DAYOFWEEK (t.created), TIME (t.created), llenas con los valores correctos usando un disparador en INSERT o UPDATE.
Ahora crea un índice de columnas múltiples (shift_id, día, hora)
Esto le permitirá tener acceso de solo lectura para la duración de los cambios:
create table_new (new schema);
insert into table_new select * from table order by primary_key_column;
rename table to table_old;
rename table_new to table;
-- recreate triggers if necessary
Cuando inserte datos en tablas InnoDB, es crucial que haga esto en el orden de las claves primarias (de lo contrario, con grandes conjuntos de datos, serán unos pocos órdenes de magnitud más lentos).