algorithm - support - SVM: ¿márgenes duros o suaves?
support vector machine regression (2)
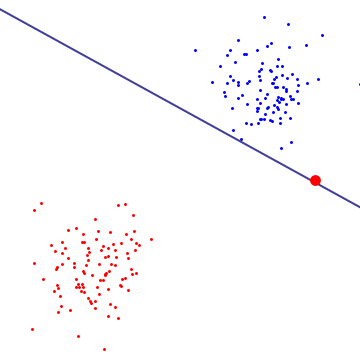
En mi opinión, Hard Margin SVM se adapta a un determinado conjunto de datos y, por lo tanto, no se puede generalizar. Incluso en un conjunto de datos separable linealmente (como se muestra en el diagrama anterior), los valores atípicos dentro de los límites pueden influir en el margen. Soft Margin SVM tiene más versatilidad porque tenemos control sobre la elección de los vectores de soporte ajustando el C.
Dado un conjunto de datos separable linealmente, ¿es necesariamente mejor usar un SVM de margen duro sobre un SVM de margen suave?
Esperaría que SVM de margen suave sea mejor incluso cuando el conjunto de datos de entrenamiento es linealmente separable. La razón es que en un SVM de margen rígido, un único valor atípico puede determinar el límite, lo que hace que el clasificador sea demasiado sensible al ruido en los datos.
En el siguiente diagrama, un único valor atípico rojo determina esencialmente el límite, que es el sello distintivo del sobreajuste
http://yaroslavvb.com/upload/save/so-svm.png
{kind=link}
Para tener una idea de lo que está haciendo soft-margin SVM, es mejor verlo en la formulación dual, donde se puede ver que tiene el mismo objetivo maximizador de márgenes (el margen podría ser negativo) que el SVM de margen rígido, pero con una restricción adicional de que cada multiplicador de lagrange asociado con el vector de soporte está limitado por C. Esencialmente esto limita la influencia de cualquier punto único en el límite de decisión, para la derivación, ver la Proposición 6.12 en "Introducción a Vector de soporte" de Cristianini / Shaw-Taylor Máquinas y otros métodos de aprendizaje basados en Kernel ".
El resultado es que SVM de margen suave podría elegir un límite de decisión que tenga un error de entrenamiento distinto de cero, incluso si el conjunto de datos es separable linealmente y es menos probable que se sobreajuste.
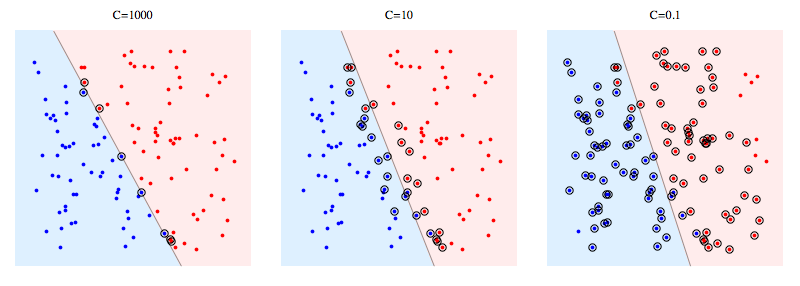
Aquí hay un ejemplo que usa libSVM en un problema sintético. Los puntos en círculo muestran vectores de soporte. Puede ver que la disminución de C hace que el clasificador sacrifique la separabilidad lineal para ganar estabilidad, en un sentido en el que la influencia de cualquier punto de datos individual ahora está limitada por C.
http://yaroslavvb.com/upload/save/so-libsvm.png
{kind=link}
Significado de los vectores de soporte:
Para SVM de margen duro, los vectores de soporte son los puntos que están "en el margen". En la imagen de arriba, C = 1000 está bastante cerca de SVM de margen rígido, y puedes ver que los puntos en un círculo son los que tocarán el margen (el margen es casi 0 en esa imagen, por lo que es esencialmente igual al hiperplano de separación )
Para SVM de márgenes suaves, es más fácil explicarlos en términos de variables duales. Su predictor vectorial de soporte en términos de variables duales es la siguiente función.
http://yaroslavvb.com/upload/save/so-svm-dual.png
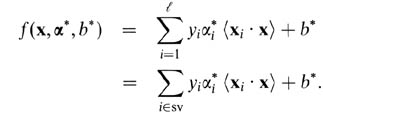{kind=link}
Aquí, alphas yb son parámetros que se encuentran durante el procedimiento de entrenamiento, xi, yi son su conjunto de entrenamiento yx es el nuevo punto de datos. Los vectores de soporte son puntos de datos del conjunto de entrenamiento que están incluidos en el predictor, es decir, los que tienen un parámetro alfa distinto de cero.