bayesiana - clasificador bayesiano python
implementación pitónica de redes bayesianas para una aplicación específica (4)
Es por eso que estoy haciendo esta pregunta: el año pasado hice un código C ++ para calcular las probabilidades posteriores para un tipo particular de modelo (descrito por una red bayesiana). El modelo funcionó bastante bien y otras personas comenzaron a usar mi software. Ahora quiero mejorar mi modelo. Como ya estoy programando algoritmos de inferencia ligeramente diferentes para el nuevo modelo, decidí usar Python porque el tiempo de ejecución no era críticamente importante y Python podría permitirme hacer un código más elegante y manejable.
Por lo general, en esta situación, buscaría un paquete de red Bayesiano existente en Python, pero los algoritmos de inferencia que estoy usando son míos, y también pensé que esta sería una gran oportunidad para aprender más sobre el buen diseño en Python.
Ya encontré un gran módulo de python para gráficos de red (networkx), que le permite adjuntar un diccionario a cada nodo y a cada borde. Esencialmente, esto me permitiría dar propiedades de nodos y bordes.
Para una red particular y sus datos observados, necesito escribir una función que calcule la probabilidad de las variables no asignadas en el modelo.
Por ejemplo, en la red clásica de "Asia" ( http://www.bayesserver.com/Resources/Images/AsiaNetwork.png ), con los estados de "XRay Result" y "Dyspnea" conocidos, necesito escribir una función para calcular la probabilidad de que las otras variables tengan ciertos valores (de acuerdo con algún modelo).
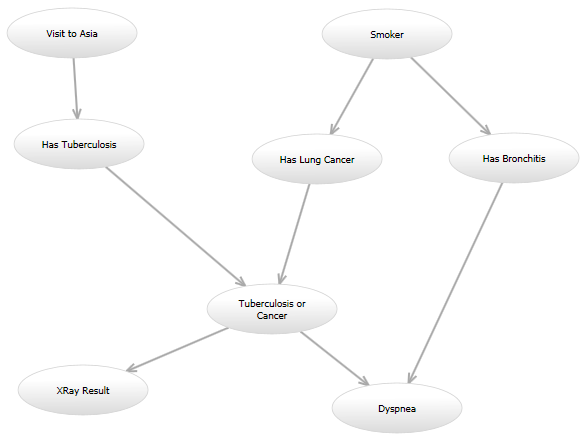{kind=link}
Aquí está mi pregunta de programación: voy a probar un puñado de modelos, y en el futuro es posible que quiera probar otro modelo después de eso. Por ejemplo, un modelo podría verse exactamente como la red de Asia. En otro modelo, se podría agregar un borde dirigido de "Visita a Asia" a "Tiene cáncer de pulmón". Otro modelo podría usar el gráfico dirigido original, pero el modelo de probabilidad para el nodo "Disnea" dado los nodos "Tuberculosis o Cáncer" y "Tiene Bronquitis" podría ser diferente. Todos estos modelos calcularán la probabilidad de una manera diferente.
Todos los modelos tendrán una superposición sustancial; por ejemplo, los múltiples bordes que entran en un nodo "O" siempre tendrán un "0" si todas las entradas son "0" y un "1" en caso contrario. Pero algunos modelos tendrán nodos que tomarán valores enteros en algún rango, mientras que otros serán booleanos.
En el pasado he luchado con la forma de programar cosas como esta. No voy a mentir; ha habido una buena cantidad de código copiado y pegado y, a veces, he necesitado propagar los cambios en un solo método a varios archivos. Esta vez, realmente quiero pasar el tiempo para hacer esto de la manera correcta.
Algunas opciones:
- Ya lo estaba haciendo de la manera correcta. Primero codifique, haga preguntas más tarde. Es más rápido copiar y pegar el código y tener una clase para cada modelo. El mundo es un lugar oscuro y desorganizado ...
- Cada modelo es su propia clase, pero también una subclase de un modelo BayesianNetwork general. Este modelo general usará algunas funciones que serán anuladas. Stroustrup estaría orgulloso.
- Realiza varias funciones en la misma clase que calculan las diferentes probabilidades.
- Codifique una biblioteca general de BayesianNetwork e implemente mis problemas de inferencia como gráficos específicos leídos por esta biblioteca. A los nodos y bordes se les deben dar propiedades como "Boolean" y "OrFunction" que, dados los estados conocidos del nodo padre, se pueden usar para calcular las probabilidades de diferentes resultados. Estas cadenas de propiedades, como "OrFunction", incluso podrían usarse para buscar y llamar a la función correcta. ¡Tal vez en un par de años haga algo similar a la versión 1988 de Mathematica!
Muchas gracias por tu ayuda.
Actualización: las ideas orientadas a objetos ayudan mucho aquí (cada nodo tiene un conjunto designado de nodos predecesores de un cierto subtipo de nodo, y cada nodo tiene una función de verosimilitud que calcula la probabilidad de diferentes estados de resultado dados los estados de los nodos predecesores, etc. ) OOP FTW!
Creo que debes hacer un par de preguntas que influyen en el diseño.
- ¿Con qué frecuencia agregará modelos?
- ¿Se espera que los consumidores de su biblioteca agreguen nuevos modelos?
- ¿Qué porcentaje de los usuarios agregará modelos frente a qué porcentaje usará los existentes?
Si la mayor parte del tiempo se gasta con los modelos existentes y los nuevos modelos serán menos comunes, entonces la herencia probablemente sea el diseño que usaría. Hace que la documentación sea fácil de estructurar y el código que la utiliza será fácil de entender.
Si el objetivo principal de la biblioteca es proporcionar una plataforma para experimentar con diferentes modelos, tomaría el gráfico con propiedades que se correlacionan con funtores para calcular cosas basadas en los padres. La biblioteca sería más compleja y la creación de gráficos sería más compleja, pero sería mucho más poderosa ya que le permitiría hacer gráficos híbridos que cambian el functor de cálculo basado en los nodos.
Independientemente del diseño final para el que trabaje, comenzaría con un diseño simple de implementación de una clase. Obténgalo pasando un conjunto de pruebas automatizadas, luego reordene en el diseño más completo después de que esté hecho. Además, no te olvides del control de la versión ;-)
El sistema de inferencia basada en restricciones Mozart / Oz3 resuelve un problema similar: describe su problema en términos de restricciones en variables de dominio finito, propagadores de restricciones y distribuidores, funciones de costos. Cuando no hay más inferencia posible, pero aún hay variables sin consolidar, utiliza las funciones de costo para dividir el espacio del problema en la variable independiente que probablemente reduce los costos de búsqueda: es decir, si X está entre [a, c] es una variable , y c (a <b <c) es el punto con mayor probabilidad de reducir el costo de búsqueda, usted termina con dos instancias de problema donde X está entre [a, b] y, en el otro caso, X está entre [b, c ] Mozart lo hace con bastante elegancia, ya que reifica la vinculación variable como un objeto de primera clase (esto es muy útil, ya que Mozart es omnipresente y está distribuido, para mover un espacio problemático a un nodo diferente). En su implementación, sospecho que emplea una estrategia de copia sobre escritura.
Seguramente puede implementar un esquema de copia por escritura en una biblioteca basada en gráficos (tip: numpy usa varias estrategias para minimizar la copia, si basa su representación gráfica en él, puede obtener la semántica de copiado-escritura de forma gratuita) y Alcanza tus metas.
He estado trabajando en este tipo de cosas en mi tiempo libre durante bastante tiempo. Creo que estoy en mi tercera o cuarta versión de este mismo problema en este momento. De hecho, me estoy preparando para lanzar otra versión de Fathom (https://github.com/davidrichards/fathom/wiki) con modelos bayesianos dinámicos incluidos y una capa de persistencia diferente.
Como traté de aclarar mi respuesta, se ha hecho bastante larga. Me disculpo por eso. Así es como he estado atacando el problema, que parece responder algunas de sus preguntas (de forma indirecta):
Empecé con la falla de Judea Pearl en la propagación de creencias en una red bayesiana. Es decir, es un gráfico con probabilidades previas (apoyo causal) proveniente de los padres y las probabilidades (soporte diagnóstico) provenientes de los niños. De esta forma, la clase básica es solo un BeliefNode, muy parecido a lo que describiste con un nodo adicional entre BeliefNodes, una LinkMatrix. De esta forma, elijo explícitamente el tipo de probabilidad que estoy usando según el tipo de LinkMatrix que uso. Hace que sea más fácil explicar lo que la red de creencias está haciendo luego, así como también simplifica el cálculo.
Cualquier subclasificación o cambio que realice en el BeliefNode básico sería para agrupar variables continuas, en lugar de cambiar reglas de propagación o asociaciones de nodos.
Decidí mantener todos los datos dentro de BeliefNode y solo reparé los datos en LinkedMatrix. Esto tiene que ver con garantizar que mantengo actualizaciones de creencias limpias con una actividad de red mínima. Esto significa que mis tiendas BeliefNode:
- una matriz de referencias de niños, junto con las probabilidades filtradas provenientes de cada niño y la matriz de enlace que está filtrando para ese niño
- una matriz de referencias principales, junto con las probabilidades previas filtradas provenientes de cada padre y la matriz de enlaces que está filtrando para ese padre
- la probabilidad combinada del nodo
- las probabilidades previas combinadas del nodo
- la creencia calculada, o probabilidad posterior
- una lista ordenada de atributos que todas las probabilidades y verosimilitudes anteriores se adhieren a
LinkMatrix se puede construir con varios algoritmos diferentes, según la naturaleza de la relación entre los nodos. Todos los modelos que estás describiendo serían clases diferentes que emplearías. Probablemente, lo más fácil de hacer es usar una puerta de enlace de manera predeterminada, y luego elegir otras formas de manejar LinkMatrix si tenemos una relación especial entre los nodos.
Yo uso MongoDB para persistencia y almacenamiento en caché. Accedo a estos datos dentro de un modelo de velocidad y acceso asíncrono. Esto hace que la red sea bastante eficiente al mismo tiempo que tiene la oportunidad de ser muy grande si es necesario. Además, dado que estoy usando Mongo de esta manera, puedo crear fácilmente un nuevo contexto para la misma base de conocimiento. Entonces, por ejemplo, si tengo un árbol de diagnóstico, parte del apoyo diagnóstico para un diagnóstico vendrá de los síntomas y las pruebas de un paciente. Lo que hago es crear un contexto para ese paciente y luego propagar mis creencias en base a la evidencia de ese paciente en particular. Del mismo modo, si un médico dijo que un paciente probablemente experimentaba dos o más enfermedades, entonces podría cambiar algunas de mis matrices de enlaces para propagar las actualizaciones de creencias de manera diferente.
Si no quiere usar algo como Mongo para su sistema, pero está planeando tener más de un consumidor trabajando en la base de conocimiento, tendrá que adoptar algún tipo de sistema de almacenamiento en caché para asegurarse de que está trabajando en forma reciente. -nodos actualizados en todo momento.
Mi trabajo es de código abierto, así que puedes seguirlo si quieres. Es todo Ruby, por lo que sería similar a tu Python, pero no necesariamente un reemplazo directo. Una cosa que me gusta de mi diseño es que toda la información necesaria para que los humanos interpreten los resultados se puede encontrar en los nodos mismos, en lugar de en el código. Esto se puede hacer en las descripciones cualitativas o en la estructura de la red.
Entonces, aquí hay algunas diferencias importantes que tengo con su diseño:
- No calculo el modelo de probabilidad dentro de la clase, sino entre nodos, dentro de la matriz de enlace. De esta forma, no tengo el problema de combinar varias funciones de verosimilitud dentro de la misma clase. Tampoco tengo el problema de un modelo frente a otro, solo puedo usar dos contextos diferentes para la misma base de conocimiento y comparar resultados.
- Estoy agregando mucha transparencia al hacer aparentes las decisiones humanas. Es decir, si decido usar una compuerta predeterminada entre dos nodos, sé cuándo agregué eso y que fue solo una decisión predeterminada. Si vuelvo más tarde y cambio la matriz de enlaces y vuelvo a calcular la base de conocimientos, tengo una nota sobre por qué lo hice, en lugar de solo una aplicación que eligió un método sobre otro. Podría hacer que sus consumidores tomen notas sobre ese tipo de cosas. Independientemente de cómo resuelva eso, probablemente sea una buena idea obtener el diálogo paso a paso del analista sobre por qué están configurando las cosas de una forma u otra.
- Puedo ser más explícito sobre probabilidades y verosimilitudes anteriores. No estoy seguro de eso, acabo de ver que estabas usando diferentes modelos para cambiar tus números de probabilidad. Mucho de lo que estoy diciendo puede ser completamente irrelevante si su modelo para calcular creencias posteriores no se descompone de esta manera. Tengo la ventaja de poder hacer tres pasos asincrónicos que se pueden llamar en cualquier orden: pasar las probabilidades cambiadas por la red, pasar las probabilidades previas modificadas por la red y volver a calcular la creencia combinada (probabilidad posterior) del nodo mismo .
Una gran advertencia: algo de lo que estoy hablando todavía no se ha lanzado. Trabajé en las cosas de las que estoy hablando hasta aproximadamente las 2:00 de esta mañana, por lo que definitivamente es actual y definitivamente recibo atención constante de mí, pero todavía no está disponible para el público. Como esta es una de mis pasiones, me complacerá responder cualquier pregunta o trabajar en conjunto en un proyecto si lo desea.
No estoy muy familiarizado con Bayesian Networks, por lo que espero que lo siguiente sea útil:
En el pasado, tuve un problema aparentemente similar con un regresor de proceso gaussiano, en lugar de un clasificador bayesiano.
Terminé usando la herencia, que funcionó muy bien. Todos los parámetros de modelo específicos se establecen con el constructor. Las funciones de calcular () son virtuales. La conexión en cascada de diferentes métodos (por ejemplo, un método suma que combina un número arbitrario de otros métodos) también funciona muy bien de esa manera.