optimization - optimized - ¿Cuánta aceleración de conversión de matemáticas 3D a SSE u otro SIMD?
seo optimized images (7)
Estoy usando matemáticas 3D en mi aplicación de manera extensiva. ¿Cuánta aceleración puedo lograr al convertir mi biblioteca vectorial / matriz a SSE, AltiVec o un código SIMD similar?
Actualmente, todos los buenos compiladores para x86 generan instrucciones SSE para matemática flotante SP y DP de forma predeterminada. Casi siempre es más rápido utilizar estas instrucciones que las nativas, incluso para operaciones escalares, siempre que las programe correctamente. Esto sorprenderá a muchos, que en el pasado descubrieron que la SSE era "lenta" y que los compiladores no podían generar instrucciones escalares de SSE rápidas. Pero ahora, debe usar un interruptor para desactivar la generación de SSE y usar x87. Tenga en cuenta que x87 está actualmente en desuso en este punto y puede ser eliminado de futuros procesadores por completo. El único inconveniente de esto es que podemos perder la capacidad de hacer flotantes DP de 80 bits en el registro. Pero el consenso parece ser que si usted está dependiendo de los flotantes DP de 80 bits en lugar de 64 bits para la precisión, debería buscar un algoritmo tolerante a la pérdida más preciso.
Todo lo anterior fue una completa sorpresa para mí. Es muy contrario a la intuición. Pero los datos hablan
En mi experiencia, normalmente veo una mejora de 3 veces en tomar un algoritmo de x87 a SSE, y una mejoría de 5x en ir a VMX / Altivec (debido a problemas complicados que tienen que ver con la profundidad de la tubería, programación, etc.). Pero generalmente solo hago esto en los casos en que tengo cientos o miles de números para operar, no para aquellos en los que hago un vector a la vez ad hoc.
Esa no es la historia completa, pero es posible obtener más optimizaciones usando SIMD, eche un vistazo a la presentación de Miguel sobre cuándo implementó las instrucciones SIMD con MONO que tuvo en PDC 2008 ,
SIMD gana al asno de dobles en esta configuración particular. http://tirania.org/tmp/xpqetp.png
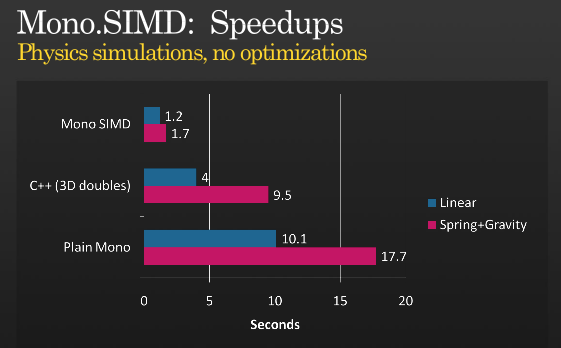{kind=link}
La respuesta depende en gran medida de lo que la biblioteca está haciendo y cómo se usa.
Las ganancias pueden ir de unos pocos puntos porcentuales, a "varias veces más rápido", las áreas más susceptibles de ver las ganancias son aquellas donde no se trata de vectores o valores aislados, sino de múltiples vectores o valores que deben procesarse en el mismo camino.
Otra área es cuando está tocando caché o límites de memoria, lo cual, de nuevo, requiere que se procesen muchos valores / vectores.
Los dominios donde las ganancias pueden ser más drásticas son probablemente los del procesamiento de imágenes y señales, las simulaciones computacionales, así como la operación general de matemáticas 3D en mallas (en lugar de vectores aislados).
Lo más probable es que solo vea una aceleración muy pequeña, si la hay, y el proceso será más complicado de lo esperado. Para obtener más detalles, consulte el artículo de la clase de vectores SSE omnipresente de Fabian Giesen.
La clase de vector SSE ubicua: Desmitificar un mito común
No es tan importante
En primer lugar, su clase vectorial probablemente no sea tan importante para el rendimiento de su programa como usted piensa (y si lo es, es más probable porque está haciendo algo mal que porque los cálculos son ineficientes). No me malinterpreten, probablemente sea una de las clases más utilizadas en todo su programa, al menos cuando se hacen gráficos en 3D. Pero el hecho de que las operaciones vectoriales sean comunes no significa automáticamente que dominarán el tiempo de ejecución de su programa.
No tan caliente
No es fácil
Ahora no
Jamas
Para algunos números muy difíciles: he escuchado que algunas personas en ompf.org reclaman aumentos de velocidad 10x para algunas rutinas de rastreo de rayos optimizadas a mano. También he tenido algunas buenas aceleraciones. Estimo que obtuve entre 2x y 6x en mis rutinas dependiendo del problema, y muchas de ellas tenían un par de tiendas y cargas innecesarias. Si tiene una gran cantidad de ramificaciones en su código, olvídese de ello, pero para problemas que son naturalmente paralelos a los datos, puede hacerlo bastante bien.
Sin embargo, debo agregar que sus algoritmos deberían estar diseñados para la ejecución paralela de datos. Esto significa que si tiene una biblioteca matemática genérica como la mencionó, debería tomar vectores empaquetados en lugar de vectores individuales o simplemente perderá su tiempo.
Por ejemplo, algo así como
namespace SIMD { class PackedVec4d { __m128 x; __m128 y; __m128 z; __m128 w; //... }; }
La mayoría de los problemas en los que el rendimiento importa se pueden paralelizar, ya que lo más probable es que esté trabajando con un gran conjunto de datos. Tu problema me parece un caso de optimización prematura.
Para operaciones 3D, tenga cuidado con los datos no inicializados en su componente W. He visto casos en los que las operaciones SSE (_mm_add_ps) tomarían un tiempo normal de 10x debido a datos incorrectos en W.