not - sqlite insert select
SQLite-UPSERT*no*INSERTAR o REEMPLAZAR (17)
http://en.wikipedia.org/wiki/Upsert
Insertar actualización almacenada proc en SQL Server
¿Hay alguna forma inteligente de hacer esto en SQLite que no haya pensado?
Básicamente, quiero actualizar tres de las cuatro columnas si el registro existe. Si no existe, quiero INSERTAR el registro con el valor predeterminado (NUL) para la cuarta columna.
La ID es una clave principal, por lo que solo habrá un registro para UPSERT.
(Estoy tratando de evitar la sobrecarga de SELECT para determinar si necesito ACTUALIZAR o INSERTAR obviamente)
Sugerencias?
No puedo confirmar esa sintaxis en el sitio SQLite para TABLE CREATE. No he creado una demo para probarlo, pero parece que no es compatible.
Si lo fuera, tengo tres columnas, así que en realidad se vería así:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
pero los dos primeros blobs no causarán un conflicto, solo la ID lo haría, así que asusme Blob1 y Blob2 no se reemplazarán (como se desee)
Las ACTUALIZACIONES en SQLite cuando los datos de enlace son una transacción completa, lo que significa que cada fila enviada a actualizarse requiere: Preparar / Enlazar / Pasar / Finalizar declaraciones a diferencia del INSERTO que permite el uso de la función de restablecimiento
La vida de un objeto de declaración es algo como esto:
- Crea el objeto usando sqlite3_prepare_v2 ()
- Vincule los valores a los parámetros del host utilizando las interfaces sqlite3_bind_.
- Ejecuta el SQL llamando a sqlite3_step ()
- Restablezca la instrucción utilizando sqlite3_reset (), luego vuelva al paso 2 y repita.
- Destruye el objeto de declaración utilizando sqlite3_finalize ().
ACTUALIZACIÓN Supongo que es lento en comparación con INSERT, pero ¿cómo se compara con SELECT utilizando la clave principal?
¿Tal vez debería usar la selección para leer la cuarta columna (Blob3) y luego REEMPLAZAR para escribir un nuevo registro que combine la cuarta columna original con los nuevos datos de las primeras 3 columnas?
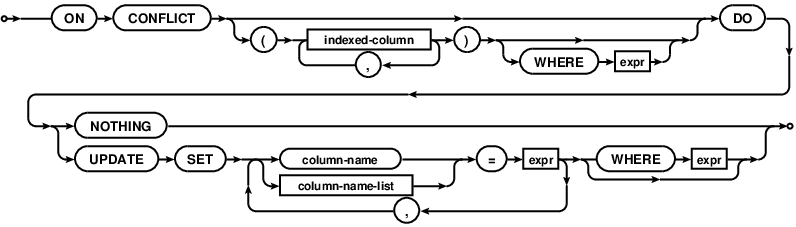
A partir de la versión 3.24.0, UPSERT es compatible con SQLite.
De la documentation :
UPSERT es una adición de sintaxis especial a INSERT que hace que INSERT se comporte como ACTUALIZACIÓN o no-op si el INSERT violaría una restricción de unicidad. UPSERT no es SQL estándar. UPSERT en SQLite sigue la sintaxis establecida por PostgreSQL. La sintaxis de UPSERT se agregó a SQLite con la versión 3.24.0 (pendiente).
Un UPSERT es una declaración INSERT ordinaria que está seguida por la cláusula especial ON CONFLICT
{kind=link}
Acabo de leer este hilo y me decepcionó que no fuera fácil solo con esta "UPSERT", investigué más ...
Realmente puedes hacer esto directamente y fácilmente en SQLITE.
En lugar de usar: INSERT INTO
Uso: INSERT OR REPLACE INTO
Esto hace exactamente lo que quieres que haga!
Ampliando share puede SELECCIONAR de una tabla ''singleton'' ficticia (una tabla de su propia creación con una sola fila). Esto evita algunas duplicaciones.
También mantuve el ejemplo portátil en MySQL y SQLite y utilicé una columna ''date_added'' como ejemplo de cómo podría establecer una columna solo la primera vez.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
Aquí hay una solución que realmente es un UPSERT (ACTUALIZACIÓN o INSERTAR) en lugar de un INSERT O REPLACE (que funciona de manera diferente en muchas situaciones).
Funciona así:
1. Intente actualizar si existe un registro con la misma ID.
2. Si la actualización no cambió ninguna fila ( NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0) ), inserte el registro.
Por lo tanto, se actualizó un registro existente o se realizará una inserción.
El detalle importante es usar la función SQL de los cambios () para verificar si la declaración de actualización llega a algún registro existente y solo realiza la instrucción de inserción si no golpeó ningún registro.
Una cosa que mencionar es que la función changes () no devuelve los cambios realizados por los activadores de nivel inferior (consulte http://sqlite.org/lang_corefunc.html#changes ), así que asegúrese de tener eso en cuenta.
Aquí está el SQL ...
Actualización de la prueba:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, ''Mike'');
INSERT INTO Contact (Id, Name) VALUES (2, ''John'');
-- Try to update an existing record
UPDATE Contact
SET Name = ''Bob''
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, ''Bob''
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Inserto de prueba:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, ''Mike'');
INSERT INTO Contact (Id, Name) VALUES (2, ''John'');
-- Try to update an existing record
UPDATE Contact
SET Name = ''Bob''
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, ''Bob''
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Creo que esto puede ser lo que está buscando: cláusula ON CONFLICT .
Si define su tabla de esta manera:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
Ahora, si realiza un INSERT con un id que ya existe, SQLite realiza ACTUALIZACIÓN de forma automática en lugar de INSERT.
Hth ...
De hecho, puedes hacer un aumento en SQLite, solo se ve un poco diferente de lo que estás acostumbrado. Se vería algo así como:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
El mejor enfoque que conozco es hacer una actualización, seguido de un inserto. La "sobrecarga de una selección" es necesaria, pero no es una carga terrible ya que está buscando la clave principal, que es rápida.
Debería poder modificar las siguientes declaraciones con los nombres de su tabla y campo para hacer lo que quiera.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
Este método remezcla algunos de los otros métodos de respuesta para esta pregunta e incorpora el uso de CTE (Common Table Expressions). Presentaré la consulta y luego explicaré por qué hice lo que hice.
Me gustaría cambiar el apellido del empleado 300 a DAVIS si hay un empleado 300. De lo contrario, agregaré un nuevo empleado.
Nombre de la tabla: empleados Columnas: id, first_name, last_name
La consulta es:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = ''300''
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, ''SALLY''),
''DAVIS''
FROM
registered_employees
;
Básicamente, utilicé el CTE para reducir el número de veces que se debe usar la declaración de selección para determinar los valores predeterminados. Dado que este es un CTE, simplemente seleccionamos las columnas que queremos de la tabla y la instrucción INSERT usa esto.
Ahora puede decidir qué valores predeterminados desea usar reemplazando los valores nulos, en la función COALESCE, con los valores que deben ser.
INSERTAR O REEMPLAZAR NO es equivalente a "UPSERT".
Digamos que tengo la tabla Empleado con los campos id, nombre y rol:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom, has perdido el nombre del empleado número 1. SQLite lo ha reemplazado con un valor predeterminado.
El resultado esperado de un UPSERT sería cambiar el rol y mantener el nombre.
Me doy cuenta de que este es un hilo antiguo, pero últimamente he estado trabajando en sqlite3 y se me ocurrió este método que se adaptaba mejor a mis necesidades de generar dinámicamente consultas parametrizadas:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
Sigue siendo 2 consultas con una cláusula where en la actualización, pero parece hacer el truco. También tengo esta visión en la cabeza de que sqlite puede optimizar completamente la declaración de actualización si la llamada a changes () es mayor que cero. Si realmente lo hace o no, eso está más allá de mi conocimiento, pero un hombre puede soñar, ¿no es así? ;)
Para los puntos de bonificación, puede agregar esta línea que le devuelve el ID de la fila, ya sea una fila recién insertada o una fila existente.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Si alguien quiere leer mi solución para SQLite en Cordova, obtuve este método js genérico gracias a la respuesta de @david anterior.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "=''" + value2 + "'', ";
sel_str = sel_str + "''" + value2 + "'', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = ''" + remoteid + "'';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
Entonces, primero recoja los nombres de columna con esta función:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type=''table'' AND name =''" + tableName + "''";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^/(]+/(([^/)]+)/)/g, ''$1'').split('',''); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === ''string'')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
Luego construye las transacciones programáticamente.
"Valores" es una matriz que debe compilar antes y representa las filas que desea insertar o actualizar en la tabla.
"remoteid" es el ID que usé como referencia, ya que estoy sincronizando con mi servidor remoto.
Para el uso del complemento SQLite Cordova, consulte el link oficial
Si en general estás haciendo actualizaciones, lo haría ..
- Comenzar una transaccion
- Hacer la actualización
- Verifica el conteo de filas
- Si es 0 haz el inserto
- Cometer
Si generalmente haces inserciones, lo haría.
- Comenzar una transaccion
- Probar un inserto
- Compruebe el error de violación de clave principal
- Si tenemos un error hacemos la actualización.
- Cometer
De esta manera, evitas la selección y eres transaccionalmente sólido en Sqlite.
Siguiendo a Aristóteles Pagaltzis y la idea de COALESCE de la respuesta de Eric B , aquí es una opción de actualización para actualizar solo algunas columnas o insertar una fila completa si no existe.
En este caso, imagine que el título y el contenido deben actualizarse, manteniendo los otros valores antiguos cuando existen e insertando los que se suministran cuando no se encuentra el nombre:
NOTA: el id se fuerza a NULL cuando se inserta, ya que se supone que es autoincremento. Si es solo una clave primaria generada, también se puede usar COALESCE (ver el comentario de Aristotle Pagaltzis ).
WITH new (id, name, title, content, author)
AS ( VALUES(100, ''about'', ''About this site'', ''Whatever new content here'', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
Entonces, la regla general sería, si desea mantener los valores antiguos, use COALESCE , cuando desee actualizar los valores, use new.fieldname
Suponiendo 3 columnas en la tabla .. ID, NOMBRE, ROL
MALO: Esto insertará o reemplazará todas las columnas con nuevos valores para ID = 1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, ''John Foo'', ''CEO'');
MALO: Esto insertará o reemplazará 2 de las columnas ... la columna NOMBRE se establecerá en NULL o el valor predeterminado:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, ''code monkey'');
BUENO: Esto actualizará 2 de las columnas. Cuando ID = 1 existe, el NOMBRE no se verá afectado. Cuando ID = 1 no existe, el nombre será el predeterminado (NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
''code monkey'',
(SELECT name FROM Employee WHERE id = 1)
);
Esto actualizará 2 de las columnas. Cuando ID = 1 existe, el ROL no se verá afectado. Cuando ID = 1 no existe, el rol se establecerá en ''Benchwarmer'' en lugar del valor predeterminado.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
''Susan Bar'',
COALESCE((SELECT role FROM Employee WHERE id = 1), ''Benchwarmer'')
);
La respuesta de Eric B está bien si desea conservar solo una o quizás dos columnas de la fila existente. Si desea conservar muchas columnas, se vuelve demasiado engorroso.
Aquí hay un enfoque que se adaptará bien a cualquier cantidad de columnas en cada lado. Para ilustrarlo asumiré el siguiente esquema:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Tenga en cuenta, en particular, que el name es la clave natural de la fila. El id se usa solo para las claves externas, por lo que el punto es que SQLite elija el valor de ID en sí al insertar una nueva fila. Pero al actualizar una fila existente en función de su name , quiero que continúe teniendo el valor de ID anterior (¡obviamente!).
UPSERT un verdadero UPSERT con la siguiente construcción:
WITH new (name, title, author) AS ( VALUES(''about'', ''About this site'', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
La forma exacta de esta consulta puede variar un poco. La clave es el uso de INSERT SELECT con una combinación externa izquierda, para unir una fila existente a los nuevos valores.
Aquí, si una fila no existía anteriormente, old.id será NULL y SQLite asignará un ID automáticamente, pero si ya existía una fila, old.id tendrá un valor real y esto se reutilizará. Que es exactamente lo que quería.
De hecho esto es muy flexible. Tenga en cuenta que la columna ts falta por completo en todos los lados, ya que tiene un valor DEFAULT , SQLite solo hará lo correcto en cualquier caso, así que no tengo que cuidarlo yo mismo.
También puede incluir una columna en los lados new y old y luego usar, por ejemplo, COALESCE(new.content, old.content) en el SELECT externo para decir "insertar el contenido nuevo si hubiera alguno; de lo contrario, mantenga el contenido antiguo" - por ejemplo, si está utilizando una consulta fija y está vinculando los nuevos valores con marcadores de posición.
2018-05-18 STOP PRESS.
Soporte de UPSERT en SQLite! La sintaxis de UPSERT se agregó a SQLite con la versión 3.24.0 (pendiente).
UPSERT es una adición de sintaxis especial a INSERT que hace que INSERT se comporte como ACTUALIZACIÓN o no-op si el INSERT violaría una restricción de unicidad. UPSERT no es SQL estándar. UPSERT en SQLite sigue la sintaxis establecida por PostgreSQL.
{kind=link}
Sé que llego tarde a la fiesta pero ...
UPDATE employee SET role = ''code_monkey'', name=''fred'' WHERE id = 1;
INSERT OR IGNORE INTO employee(id, role, name) values (1, ''code monkey'', ''fred'');
Entonces intenta actualizar, si el registro está allí, entonces la inserción no es de acción.
alternativamente:
Otra forma completamente diferente de hacer esto es: En mi aplicación, configuro mi ID de fila de memoria para que sea larga. Valor máx. Cuando creo la fila en la memoria. (MaxValue nunca se usará como ID, no vivirá lo suficiente ... Entonces, si rowID no tiene ese valor, ya debe estar en la base de datos, por lo que necesita una ACTUALIZACIÓN si es MaxValue, entonces necesita una inserción. Esto solo es útil si puede hacer un seguimiento de los ID de fila en su aplicación.
SELECT COUNT(*) FROM table1 WHERE id = 1;
si COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
más si COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;