¿Por qué necesitamos intermediarios de mensajes como RabbitMQ en una base de datos como PostgreSQL?
redis message-queue (2)
PostgreSQL 9.5
PostgreSQL 9.5 incorpora SELECT ... FOR UPDATE ... SKIP LOCKED . Esto hace que la implementación de sistemas de cola de trabajo sea mucho más simple y fácil. Es posible que ya no necesite un sistema de colas externo, ya que ahora es fácil buscar ''n'' filas que ninguna otra sesión ha bloqueado y mantenerlas cerradas hasta que confirme que el trabajo está terminado. Incluso funciona con transacciones en dos fases para cuando se requiere coordinación externa.
Los sistemas de colas externas siguen siendo útiles, ya que brindan funcionalidad enlatada, rendimiento comprobado, integración con otros sistemas, opciones de escalado horizontal y federación, etc. No obstante, para casos simples ya no los necesita.
versiones anteriores
No necesita tales herramientas, pero usar una puede hacer la vida más fácil. Hacer colas en la base de datos parece fácil, pero en la práctica descubrirá que las colas concurrentes confiables y de alto rendimiento son realmente difíciles de hacer en una base de datos relacional.
Es por eso que existen herramientas como PGQ .
Puedes deshacerte de las encuestas en PostgreSQL usando LISTEN y NOTIFY , pero eso no resolverá el problema de entregar de manera confiable entradas de la parte superior de la cola a exactamente un consumidor mientras se preserva el funcionamiento altamente concurrente y no se bloquean las inserciones. Todas las soluciones simples y obvias que crees que resolverán ese problema en realidad no existen en el mundo real, y tienden a degenerar en versiones menos eficientes de la recuperación de colas para un solo trabajador.
Si no necesita recuperaciones de colas multi-worker altamente concurrentes, usar una sola tabla de colas en PostgreSQL es completamente razonable.
Soy nuevo en los corredores de mensajes como RabbitMQ que podemos usar para crear tareas / colas de mensajes para un sistema de programación como Celery .
Ahora, aquí está la pregunta:
Puedo crear una tabla en PostgreSQL que pueda agregarse a tareas nuevas y consumirse en el programa de consumo, como Apio.
¿Por qué querría configurar una tecnología completamente nueva para esto como RabbitMQ?
Ahora, creo que escalar no puede ser la respuesta, ya que nuestra base de datos, como PostgreSQL, puede funcionar en un entorno distribuido.
Busqué en Google qué problemas plantea la base de datos para el problema en particular, y encontré:
- sondeo manteniendo la base de datos ocupada y de bajo rendimiento
- bloqueo de la mesa -> de nuevo bajo rendimiento
- millones de filas de tareas -> nuevamente las encuestas tienen bajo rendimiento
Ahora, ¿cómo resuelve RabbitMQ o cualquier otro intermediario de mensajes estos problemas?
Además, descubrí que el protocolo AMQP es lo que sigue. ¿Qué hay de bueno en eso?
¿Se puede usar también Redis como intermediario de mensajes? Encuentro más análogo a Memcache que a RabbitMQ.
¡Por favor alumbrame esto!
Las colas de Rabbit residen en la memoria y, por lo tanto, serán mucho más rápidas que implementarlas en una base de datos. Una (buena) cola de mensajes dedicada también debe proporcionar características esenciales relacionadas con la cola de espera, como el control de velocidad / flujo y la capacidad de elegir diferentes algoritmos de enrutamiento, por nombrar a una pareja (rabbit proporciona estos y más). Dependiendo del tamaño de su proyecto, también puede desear que el componente de paso de mensajes se separe de su base de datos, de modo que si un componente experimenta una gran carga, no debe obstaculizar el funcionamiento del otro.
En cuanto a los problemas que mencionaste:
sondeos manteniendo la base de datos deficiente y de bajo rendimiento : al usar Rabbitmq, los productores pueden enviar actualizaciones a los consumidores, lo que es mucho más eficiente que el sondeo. Los datos simplemente se envían al consumidor cuando es necesario, eliminando la necesidad de controles innecesarios.
bloqueo de la mesa -> de nuevo bajo rendimiento: no hay mesa para bloquear: P
millones de filas de tareas -> nuevo sondeo de bajo rendimiento: como se mencionó anteriormente, Rabbitmq operará más rápido ya que reside RAM, y proporciona control de flujo. Si es necesario, también puede usar el disco para almacenar mensajes temporalmente si se queda sin memoria RAM. Después de 2.0, Rabbit ha mejorado significativamente en su uso de RAM. Las opciones de agrupamiento también están disponibles.
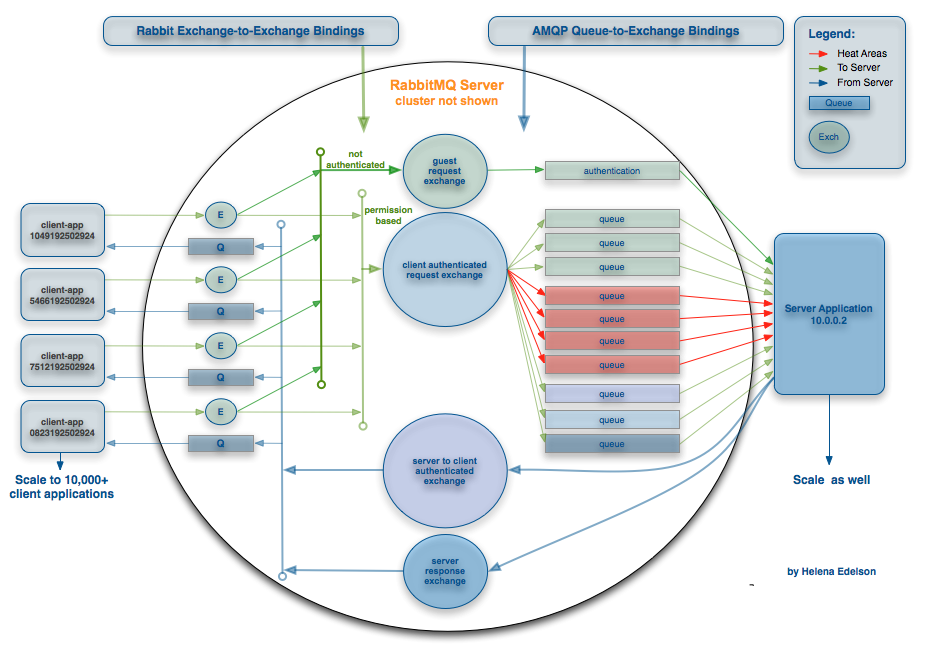
Con respecto a AMQP, diría que una característica realmente genial es el "intercambio", y la posibilidad de que se dirija a otros intercambios. Esto le da más flexibilidad y le permite crear una amplia gama de tipologías de enrutamiento elaboradas que pueden ser muy útiles al escalar. Para un buen ejemplo, ver:
http://blog.springsource.com/wp-content/uploads/2011/04/routing-topology.png
{kind=link}
Finalmente, en lo que respecta a redis, sí, se puede utilizar como intermediario de mensajes y puede hacerlo bien. Sin embargo, Rabbitmq tiene más funciones de encolamiento de mensajes que redis, ya que rabbitmq se construyó desde cero para ser una cola de mensajes dedicada de nivel empresarial con todas las funciones. Redis, por otro lado, fue creado principalmente para ser un almacén de valores-clave en la memoria (aunque ahora hace mucho más que eso, incluso se lo conoce como una navaja suiza). Aún así, he leído / escuchado a muchas personas que logran buenos resultados con Redis para proyectos de menor tamaño, pero no han escuchado mucho sobre esto en aplicaciones más grandes.
Aquí hay un ejemplo de redis que se usa en una implementación de chat de larga duración: http://eflorenzano.com/blog/2011/02/16/technology-behind-convore/