estandar - estadistica con python pdf
Cálculo de covarianza con Python y Numpy (2)
Estoy tratando de averiguar cómo calcular la covarianza con la función de Python Numpy cov. Cuando lo paso dos matrices de una dimensión, obtengo una matriz de resultados de 2x2. No sé qué hacer con eso. No soy bueno para las estadísticas, pero creo que la covarianza en una situación así debería ser un número único. This es lo que estoy buscando. Yo escribí el mío:
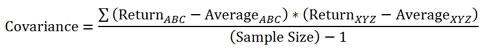{kind=link}
def cov(a, b):
if len(a) != len(b):
return
a_mean = np.mean(a)
b_mean = np.mean(b)
sum = 0
for i in range(0, len(a)):
sum += ((a[i] - a_mean) * (b[i] - b_mean))
return sum/(len(a)-1)
Eso funciona, pero me imagino que la versión de Numpy es mucho más eficiente, si pudiera descubrir cómo usarla.
¿Alguien sabe cómo hacer que la función Nuvy cov funcione como la que escribí?
Gracias,
Dave
Cuando a y b son secuencias de 1 dimensión, numpy.cov(a,b)[0][1] es equivalente a su cov(a,b) .
La matriz 2x2 devuelta por np.cov(a,b) tiene elementos iguales a
cov(a,a) cov(a,b)
cov(a,b) cov(b,b)
(donde, de nuevo, cov es la función que definiste arriba).
Gracias a Unutbu por la explicación. Por defecto, numpy.cov calcula la covarianza de la muestra. Para obtener la covarianza poblacional puede especificar la normalización por el total de N muestras como esta:
Covariance = numpy.cov(a, b, bias=True)[0][1]
print(Covariance)
o así:
Covariance = numpy.cov(a, b, ddof=0)[0][1]
print(Covariance)