programacion - División eficiente de punto flotante con divisores de números enteros constantes
punto flotante ejemplos (4)
Una question reciente, si los compiladores pueden reemplazar la división de punto flotante con la multiplicación de coma flotante, me inspiró a hacer esta pregunta.
Bajo el estricto requisito de que los resultados después de la transformación del código sean idénticos en bit a la operación de división real, es trivial ver que para la aritmética binaria IEEE-754, esto es posible para divisores que tienen una potencia de dos. Siempre que el recíproco del divisor sea representable, al multiplicarse por el recíproco del divisor se obtienen resultados idénticos a la división. Por ejemplo, la multiplicación por 0.5 puede reemplazar la división por 2.0 .
Uno se pregunta por qué otros divisores funcionan, suponiendo que permitamos cualquier secuencia breve de instrucciones que reemplace a la división pero que se ejecute significativamente más rápido, al mismo tiempo que entrega resultados idénticos a los bits. En particular, permite operaciones fusionadas de suma y multiplicación además de la multiplicación simple. En los comentarios, señalé el siguiente documento relevante:
Nicolas Brisebarre, Jean-Michel Muller y Saurabh Kumar Raina. Acelerando la división de coma flotante correctamente redondeada cuando se conoce con anticipación al divisor. Transacciones IEEE en computadoras, vol. 53, No. 8, agosto de 2004, págs. 1069-1072.
La técnica preconizada por los autores del documento calcula previamente el recíproco del divisor y como un par cabeza-cola normalizado z h : z l de la siguiente manera: z h = 1 / y, z l = fma (-y, z h , 1 ) / y . Más tarde, la división q = x / y se calcula como q = fma (z h , x, z l * x) . El documento deriva varias condiciones que el divisor y debe satisfacer para que este algoritmo funcione. Como uno observa fácilmente, este algoritmo tiene problemas con infinitos y cero cuando los signos de cabeza y cola son diferentes. Lo que es más importante, no ofrecerá resultados correctos para los dividendos x que sean de magnitud muy pequeña, ya que el cómputo del cociente del cociente, z l * x , sufre un subdesbordamiento.
El documento también hace una referencia pasajera a un algoritmo alternativo de división basado en FMA, iniciado por Peter Markstein cuando estaba en IBM. La referencia relevante es:
PW Markstein. Cálculo de funciones elementales en el procesador IBM RISC System / 6000. IBM Journal of Research & Development, vol. 34, No. 1, enero de 1990, págs. 111-119
En el algoritmo de Markstein, uno primero calcula un rc recíproco, a partir del cual se forma un cociente inicial q = x * rc . Luego, el resto de la división se calcula con precisión con una FMA como r = fma (-y, q, x) , y un cociente mejorado y más preciso finalmente se calcula como q = fma (r, rc, q) .
Este algoritmo también tiene problemas para x que son ceros o infinitos (fáciles de solucionar con la ejecución condicional adecuada), pero las pruebas exhaustivas con datos float precisión simple IEEE-754 muestran que proporciona el cociente correcto en todos los dividendos posibles x para muchos divisores y , entre estos muchos enteros pequeños. Este código C lo implementa:
/* precompute reciprocal */
rc = 1.0f / y;
/* compute quotient q=x/y */
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
En la mayoría de las arquitecturas de procesadores, esto debería traducirse en una secuencia de instrucciones sin ramas, utilizando predicción, movimientos condicionales o instrucciones de tipo de selección. Para dar un ejemplo concreto: para la división por 3.0f , el compilador nvcc de CUDA 7.5 genera el siguiente código de máquina para una GPU de clase Kepler:
LDG.E R5, [R2]; // load x
FSETP.NEU.AND P0, PT, |R5|, +INF , PT; // pred0 = fabsf(x) != INF
FMUL32I R2, R5, 0.3333333432674408; // q = x * (1.0f/3.0f)
FSETP.NEU.AND P0, PT, R5, RZ, P0; // pred0 = (x != 0.0f) && (fabsf(x) != INF)
FMA R5, R2, -3, R5; // r = fmaf (q, -3.0f, x);
MOV R4, R2 // q
@P0 FFMA R4, R5, c[0x2][0x0], R2; // if (pred0) q = fmaf (r, (1.0f/3.0f), q)
ST.E [R6], R4; // store q
Para mis experimentos, escribí el pequeño programa de prueba C que se muestra a continuación que avanza a través de divisores enteros en orden creciente y para cada uno de ellos prueba exhaustivamente la secuencia de códigos anterior en contra de la división correcta. Imprime una lista de los divisores que aprobaron esta prueba exhaustiva. La salida parcial se ve de la siguiente manera:
PASS: 1, 2, 3, 4, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 23, 25, 27, 29, 31, 32, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 64, 65, 67, 69,
Para incorporar el algoritmo de reemplazo en un compilador como una optimización, una lista blanca de divisores a los que la transformación de código anterior se puede aplicar con seguridad no es práctica. La salida del programa hasta el momento (a razón de aproximadamente un resultado por minuto) sugiere que el código rápido funciona correctamente en todas las codificaciones posibles de x para esos divisores y que son enteros impares o son potencias de dos. Evidencia anecdótica, no una prueba, por supuesto.
¿Qué conjunto de condiciones matemáticas puede determinar a priori si la transformación de la división en la secuencia de código anterior es segura? Las respuestas pueden suponer que todas las operaciones de coma flotante se realizan en el modo de redondeo predeterminado de "redondear al más cercano o par".
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int main (void)
{
float r, q, x, y, rc;
volatile union {
float f;
unsigned int i;
} arg, res, ref;
int err;
y = 1.0f;
printf ("PASS: ");
while (1) {
/* precompute reciprocal */
rc = 1.0f / y;
arg.i = 0x80000000;
err = 0;
do {
/* do the division, fast */
x = arg.f;
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
res.f = q;
/* compute the reference, slowly */
ref.f = x / y;
if (res.i != ref.i) {
err = 1;
break;
}
arg.i--;
} while (arg.i != 0x80000000);
if (!err) printf ("%g, ", y);
y += 1.0f;
}
return EXIT_SUCCESS;
}
Déjame reiniciar por tercera vez. Estamos tratando de acelerar
q = x / y
donde y es una constante entera, q , y son todos los valores de coma flotante binary32 de IEEE 754-2008 . A continuación, fmaf(a,b,c) indica un múltiplo-agregar fusionado a * b + c usando valores binarios32.
El algoritmo ingenuo es a través de un recíproco precalculado,
C = 1.0f / y
de modo que en el tiempo de ejecución una multiplicación (mucho más rápida) sea suficiente:
q = x * C
La aceleración Brisebarre-Muller-Raina usa dos constantes precalculadas,
zh = 1.0f / y
zl = -fmaf(zh, y, -1.0f) / y
de modo que en tiempo de ejecución, una multiplicación y un multiplicado-suma fusionadas sean suficientes:
q = fmaf(x, zh, x * zl)
El algoritmo de Markstein combina el enfoque ingenuo con dos fusiones multiplicadas que arrojan el resultado correcto si el enfoque ingenuo produce un resultado dentro de 1 unidad en el lugar menos significativo, al calcular previamente
C1 = 1.0f / y
C2 = -y
para que la división se pueda aproximar usando
t1 = x * C1
t2 = fmaf(C1, t1, x)
q = fmaf(C2, t2, t1)
El enfoque ingenuo funciona para todos los poderes de dos y , pero por lo demás es bastante malo. Por ejemplo, para los divisores 7, 14, 15, 28 y 30, arroja un resultado incorrecto para más de la mitad de todas las posibles x .
El enfoque de Brisebarre-Muller-Raina falla de manera similar para casi todos los no-poderes de dos y , pero mucho menos x rinde el resultado incorrecto (menos del medio por ciento de todas las x posibles, varía según y ).
El artículo de Brisebarre-Muller-Raina muestra que el error máximo en el enfoque ingenuo es de ± 1.5 ULP.
El enfoque de Markstein arroja resultados correctos para las potencias de dos y , y también para el entero impar y . (No he encontrado un divisor de entero impar que falla para el enfoque de Markstein.)
Para el enfoque de Markstein, he analizado los divisores 1 - 19700 ( datos brutos aquí ).
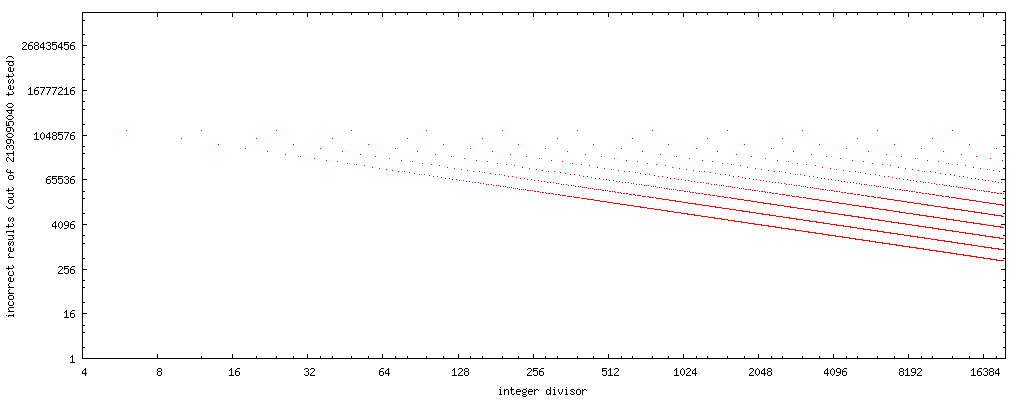
Al trazar el número de casos de falla (divisor en el eje horizontal, el número de valores de x donde falla el enfoque de Markstein para dicho divisor), podemos ver que se produce un patrón simple:
Casos de falla de Markstein http://www.nominal-animal.net/answers/markstein.png
{kind=link}
Tenga en cuenta que estas gráficas tienen logaritmos tanto horizontales como verticales. No hay puntos para los divisores impares, ya que el enfoque arroja resultados correctos para todos los divisores impares que he probado.
Si cambiamos el eje x por el bit inverso (dígitos binarios en orden inverso, es decir, 0b11101101 → 0b10110111, data ) de los divisores, tenemos un patrón muy claro: casos de fallas de Markstein, divisor de bit inverso http: //www.nominal- animal.net/answers/markstein-failures.png
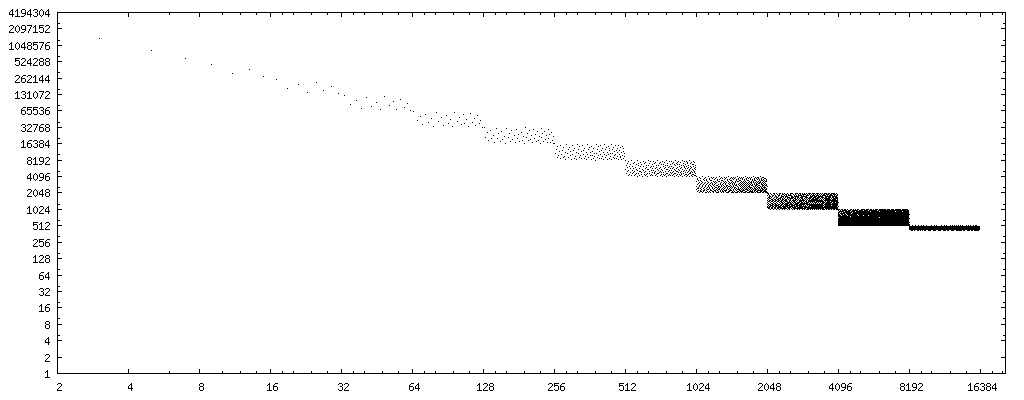{kind=link}
Si dibujamos una línea recta a través del centro de los conjuntos de puntos, obtenemos la curva 4194304/x . (Recuerde que la gráfica considera solo la mitad de los flotantes posibles, por lo tanto, cuando considere todos los flotantes posibles, 8388608/x ). 8388608/x y 2097152/x corchetean completamente el patrón de error.
Por lo tanto, si usamos rev(y) para calcular el bit inverso del divisor y , entonces 8388608/rev(y) es una buena aproximación de primer orden del número de casos (de todas las posibles fluctuaciones) donde el enfoque de Markstein arroja un resultado incorrecto resultado para un divisor par, sin poder de dos. (O bien, 16777216/rev(x) para el límite superior).
Agregado 2016-02-28: Encontré una aproximación para el número de casos de error usando el enfoque Markstein, dado cualquier divisor entero (binario32). Aquí está como pseudocódigo:
function markstein_failure_estimate(divisor):
if (divisor is zero)
return no estimate
if (divisor is not an integer)
return no estimate
if (divisor is negative)
negate divisor
# Consider, for avoiding underflow cases,
if (divisor is very large, say 1e+30 or larger)
return no estimate - do as division
while (divisor > 16777216)
divisor = divisor / 2
if (divisor is a power of two)
return 0
if (divisor is odd)
return 0
while (divisor is not odd)
divisor = divisor / 2
# Use return (1 + 83833608 / divisor) / 2
# if only nonnegative finite float divisors are counted!
return 1 + 8388608 / divisor
Esto arroja una estimación de error correcta dentro de ± 1 en los casos de falla de Markstein que he probado (pero todavía no he probado adecuadamente los divisores más grandes que 8388608). La división final debería ser tal que no reporte ceros falsos, pero no puedo garantizarlo (todavía). No toma en cuenta divisores muy grandes (digamos 0x1p100, o 1e + 30, y de mayor magnitud) que tienen problemas de subdesbordamiento - Definitivamente excluiría dichos divisores de la aceleración de todos modos.
En las pruebas preliminares, la estimación parece asombrosamente precisa. No dibujé un diagrama comparando las estimaciones y los errores reales para los divisores 1 a 20000, porque todos los puntos coinciden exactamente en las tramas. (Dentro de este rango, la estimación es exacta, o una muy grande.) Esencialmente, las estimaciones reproducen exactamente la primera gráfica en esta respuesta.
El patrón de fallas para el enfoque de Markstein es regular y muy interesante. El enfoque funciona para toda la potencia de dos divisores y todos los divisores de números enteros impares.
Para divisores mayores que 16777216, veo consistentemente los mismos errores que para un divisor que se divide por la potencia más pequeña de dos para obtener un valor menor que 16777216. Por ejemplo, 0x1.3cdfa4p + 23 y 0x1.3cdfa4p + 41, 0x1. d8874p + 23 y 0x1.d8874p + 32, 0x1.cf84f8p + 23 y 0x1.cf84f8p + 34, 0x1.e4a7fp + 23 y 0x1.e4a7fp + 37. (Dentro de cada par, la mantisa es la misma, y solo el poder de dos varía).
Asumiendo que mi banco de pruebas no está en error, esto significa que el enfoque de Markstein también funciona con divisores mayores a 16777216 en magnitud (pero más pequeños que, digamos, 1e + 30), si el divisor es tal que cuando se divide por el poder más pequeño de dos produce un cociente de menos de 16777216 en magnitud, y el cociente es impar.
El resultado de una división de coma flotante es:
- una bandera de letrero
- un significado
- un exponente
- un conjunto de indicadores (desbordamiento, desbordamiento, inexacto, etc.) - vea
fenv())
Obtener las primeras 3 piezas correctas (pero el conjunto de indicadores incorrecto) no es suficiente. Sin más conocimiento (por ejemplo, qué partes del resultado realmente importan, los posibles valores del dividendo, etc.) supondría que reemplazar la división por una constante con la multiplicación por una constante (y / o un complicado desorden de FMA) es casi nunca a salvo.
En adición; para las CPU modernas tampoco supongo que reemplazar una división con 2 FMA es siempre una mejora. Por ejemplo, si el cuello de botella es instrucción fetch / decode, entonces esta "optimización" empeoraría el rendimiento. Para otro ejemplo, si las instrucciones posteriores no dependen del resultado (la CPU puede hacer muchas otras instrucciones en paralelo mientras se espera el resultado), la versión de FMA puede introducir múltiples puestos de dependencia y empeorar el rendimiento. Para un tercer ejemplo, si se usan todos los registros, la versión de FMA (que requiere variables "activas" adicionales) puede aumentar el "derrame" y empeorar el rendimiento.
Tenga en cuenta que (en muchos, pero no en todos los casos) la división o multiplicación por un múltiplo constante de 2 se puede hacer con suma solamente (específicamente, agregar un recuento de turno al exponente).
Esta pregunta requiere una forma de identificar los valores de la constante Y que hace que sea seguro transformar x / Y en un cálculo más barato usando FMA para todos los valores posibles de x . Otro enfoque es usar análisis estático para determinar una sobre-aproximación de los valores que x puede tomar, de modo que la transformación generalmente poco sólida pueda aplicarse con el conocimiento de que los valores para los cuales el código transformado difiere de la división original no ocurren.
Al usar representaciones de conjuntos de valores de coma flotante que están bien adaptados a los problemas de los cálculos de coma flotante, incluso un análisis hacia adelante comenzando desde el comienzo de la función puede producir información útil. Por ejemplo:
float f(float z) {
float x = 1.0f + z;
float r = x / Y;
return r;
}
Asumiendo el modo predeterminado de redondear al más cercano (*), en la función anterior x solo puede ser NaN (si la entrada es NaN), + 0.0f, o un número mayor que 2 -24 en magnitud, pero no -0.0f o algo más cercano a cero que 2 -24 . Esto justifica la transformación en una de las dos formas que se muestran en la pregunta para muchos valores de la constante Y
(*) suposición sin la cual muchas optimizaciones son imposibles y que los compiladores de C ya hacen a menos que el programa use explícitamente #pragma STDC FENV_ACCESS ON
Un análisis estático directo que predice la información para x arriba se puede basar en una representación de conjuntos de valores de punto flotante que una expresión puede tomar como una tupla de:
- una representación para los conjuntos de posibles valores de NaN (dado que los comportamientos de NaN están subespecificados, una opción es usar solo un booleano, con
truesignificado algunos NaN pueden estar presentes, yfalseindica que no está presente NaN), - cuatro indicadores booleanos que indican respectivamente la presencia de + inf, -inf, +0.0, -0.0,
- un intervalo inclusivo de valores de coma flotante finitos negativos, y
- un intervalo inclusivo de valores de coma flotante finitos positivos.
Para seguir este enfoque, todas las operaciones de coma flotante que puedan ocurrir en un programa C deben ser entendidas por el analizador estático. Para ilustrar, los conjuntos de valores de adición U y V, que se utilizarán para manejar + en el código analizado, se pueden implementar como:
- Si NaN está presente en uno de los operandos, o si los operandos pueden ser infinitos de signos opuestos, NaN está presente en el resultado.
- Si 0 no puede ser el resultado de la adición de un valor de U y un valor de V, utilice la aritmética de intervalos estándar. El límite superior del resultado se obtiene para la adición de redondear al más cercano del valor más grande en U y el valor más grande en V, por lo que estos límites se deben calcular con redondeo a más cercano.
- Si 0 puede ser el resultado de la adición de un valor positivo de U y un valor negativo de V, entonces, que M sea el valor positivo más pequeño en U tal que -M esté presente en V.
- si succ (M) está presente en U, entonces este par de valores contribuye succ (M) - M a los valores positivos del resultado.
- si -succ (M) está presente en V, entonces este par de valores contribuye con el valor negativo M - succ (M) a los valores negativos del resultado.
- si pred (M) está presente en U, entonces este par de valores contribuye con el valor negativo pred (M) - M a los valores negativos del resultado.
- si -pred (M) está presente en V, entonces este par de valores contribuye con el valor M - pred (M) a los valores positivos del resultado.
- Haga el mismo trabajo si 0 puede ser el resultado de la adición de un valor negativo de U y un valor positivo de V.
Reconocimiento: lo anterior toma prestado ideas de "Mejorando las restricciones de suma y resta de punto flotante", Bruno Marre y Claude Michel
Ejemplo: compilación de la función f continuación:
float f(float z, float t) {
float x = 1.0f + z;
if (x + t == 0.0f) {
float r = x / 6.0f;
return r;
}
return 0.0f;
}
El enfoque en la pregunta se rehúsa a transformar la división en función f en una forma alternativa, porque 6 no es uno de los valores para los que la división puede ser transformada incondicionalmente. En cambio, lo que estoy sugiriendo es aplicar un análisis de valor simple comenzando desde el comienzo de la función que, en este caso, determina que x es un flotador finito ya sea +0.0f o al menos 2 -24 en magnitud, y para usar esto información para aplicar la transformación de Brisebarre et al, confiada en el conocimiento de que x * C2 no se desborda.
Para ser explícito, sugiero usar un algoritmo como el siguiente para decidir si se debe transformar o no la división en algo más simple:
- ¿Es
Yuno de los valores que se pueden transformar usando el método de Brisebarre et al según su algoritmo? - ¿C1 y C2 de su método tienen el mismo signo, o es posible excluir la posibilidad de que el dividendo sea infinito?
- ¿C1 y C2 de su método tienen el mismo signo, o pueden tomar
xsolo una de las dos representaciones de 0? Si en el caso en que C1 y C2 tienen signos diferentes yxsolo puede ser una representación de cero, recuerde virar (**) con los signos del cálculo basado en FMA para hacer que produzca el cero correcto cuandoxes cero. - ¿Se puede garantizar que la magnitud del dividendo sea lo suficientemente grande como para excluir la posibilidad de que
x * C2desborde?
Si la respuesta a las cuatro preguntas es "sí", entonces la división se puede transformar en una multiplicación y una FMA en el contexto de la función que se está compilando. El análisis estático descrito anteriormente sirve para responder a las preguntas 2., 3. y 4.
(**) "juguetear con los signos" significa usar -FMA (-C1, x, (-C2) * x) en lugar de FMA (C1, x, C2 * x) cuando sea necesario para que el resultado salga correctamente cuando x solo puede ser uno de los dos ceros firmados
Me encanta la respuesta de , pero en la optimización a menudo es mejor tener un subconjunto de transformaciones simple y bien entendido en lugar de una solución perfecta.
Todos los formatos de puntos flotantes históricos actuales y comunes tenían una cosa en común: una mantisa binaria.
Por lo tanto, todas las fracciones eran números racionales de la forma:
x / 2 n
Esto está en contraste con las constantes en el programa (y todas las posibles fracciones de base-10) que son números racionales de la forma:
x / (2 n * 5 m )
Entonces, una optimización simplemente probaría la entrada y recíproca para m == 0, ya que esos números están representados exactamente en el formato FP y las operaciones con ellos deberían producir números que sean precisos dentro del formato.
Entonces, por ejemplo, dentro del rango (decimal de 2 dígitos) de .01 a 0.99 se optimizaría la división o multiplicación por los siguientes números:
.25 .50 .75
Y todo lo demás no. (Creo que prueba primero, jaja.)