rdf - ¿Qué es la web semántica?
semantics semantic-web (10)
¿Cómo será diferente a la web que conocemos ahora?
En este momento, el HTML + CSS se centra más en la estructura y la presentación. La semántica es sobre el significado de la información. En la web semántica, se usan ontologies compartidas para establecer el significado (semántico) del objeto y el significado de las relaciones entre los objetos. Las ontologías más conocidas son: FOAF y Dublin Core .
Normalmente, la semántica se expresaría en un lenguaje especializado, como RDF u OWL . RDF se puede incrustar en XHTML utilizando eRDF o RDFa de W3C.
Las alternativas menos estructuradas a eRDF / RDFa son los microformats .
Lea más en: http://en.wikipedia.org/wiki/Semantic_web
He oído mucho sobre la web semántica, pero todavía no estoy muy seguro de qué es. ¿Cómo será diferente a la web que conocemos ahora?
Es una palabra de moda para atraer el interés de la gente, similar a la web 2.0
Es decir, en el futuro, el contenido se dividirá de la presentación y permitirá mucha bondad.
En realidad, los hechos serán subjetivos, dependiendo de la realidad y autoridad del anfitrión.
En otras palabras, los usuarios no verán mucha diferencia a partir de ahora.
La Web Semántica es un sistema de información distribuida donde los datos interconectados se publican como tripletas RDF sobre HTTP. Los tripletes RDF constan de sujeto, predicado y objeto, pero pueden tener otras cosas adjuntas, como tipos de datos y anotaciones sobre el lenguaje natural de los objetos. En la Web semántica, los URI se utilizan como identificadores y como direcciones de recursos de red.
Es diferente de la Web, porque la Web es un sistema de información distribuida de documentos e interfaces de aplicaciones.
La Web semántica es en el fondo una idea muy simple. (Como todos los buenos.)
La web en la actualidad consta de documentos con enlaces entre ellos. Google ha hecho un buen negocio utilizando el contexto y el texto de anclaje dentro de los enlaces, para averiguar qué significan los enlaces y construir un motor para recuperar datos basados en eso. En otras palabras, Google hace una estimación del significado semántico de un enlace.
La idea de la Web Semántica es "¿qué pasaría si se escribieran estos enlaces?" Cada hecho en la Web obtiene una dirección (un URI) y está vinculado a otros hechos (también URI) por relaciones ( también URI). Los grupos de relaciones se llaman "ontologías".
Entonces, en lugar de los enlaces de la página A a la página B, como en la web actual, los enlaces de la Web Semántica son más como:
URI A enlaza con URI B con un enlace de tipo URI C.
Cualquier cosa puede tener un URI. Las personas pueden tener URI; Usualmente usamos un conjunto de relaciones llamado FOAF para describirlas. Así que digamos que el URI para Jeff Atwood es http://codinghorror.com/foaf.xml ; entonces podrías decir:
< http://codinghorror.com > < http://xmlns.com/foaf/0.1/homepage > < http://codinghorror.com/foaf.xml >
es decir, http://codinghorror.com es la página de inicio de la persona representada por el contenido de http://codinghorror.com/foaf.xml .
Ahora las máquinas pueden leer y consultar estas relaciones, por lo que convierte la Web en una base de datos con la que las computadoras pueden hacer algo de inmediato. El lenguaje de consulta de la Web Semántica es SPARQL, y vale la pena echarle un vistazo.
La Web semántica es lo que Tim Berners-Lee, el inventor de la World Wide Web, realmente quería que fuera la Web, es decir, un gráfico global de datos interconectados. Es una generalización de un gráfico social , donde puede utilizar datos sociales (con vocabularios como FOAF ), así como cualquier otro tipo de datos comprensibles por máquina y conectarlos entre sí. Los formatos estándar para describir esta información a las máquinas son el Formato de Descripción de Recursos ( RDF ) y el Lenguaje de Ontología Web ( OWL ). Ya hay una gran cantidad de datos codificados en la Web, incluida una versión RDF de Wikipedia, llamada DBPedia .
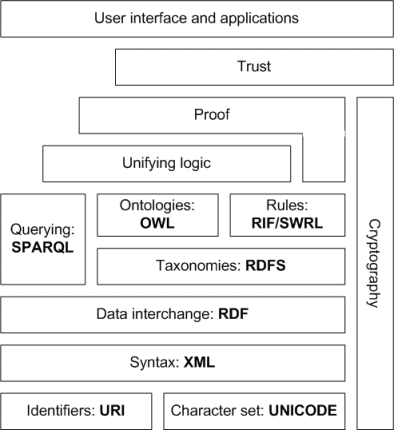
La Web semántica será diferente a la Web de hoy en día, ya que tanto las computadoras como los humanos entenderán qué contienen los documentos y cuál es la importancia de los vínculos entre los documentos. Esto facilitará la automatización de las tareas de procesamiento de información, incluida la búsqueda de información de fuentes confiables. La pila completa de SemWeb incluye criptografía, sistemas de prueba y redes de confianza.
{kind=link}
La Web semántica es solo eso: una capa semántica (significativa) sobre la WWW. Es semi estructurado (RDF), se autodescribe (ontologías usando OWL) y permite el descubrimiento de recursos (SPARQL).
La Web semántica trabaja bajo la premisa de la suposición del "mundo abierto"; el hecho de que algo no esté enunciado no significa que no exista, simplemente es "desconocido". Esta es una lógica fundamentalmente diferente a la utilizada en un RDBMS como MySQL et al. - si falta algo, no existe - suposición de "mundo cerrado". Prolog y DATALOG son buenos ejemplos de lógicas de Close World.
Si desea conocer realmente lo que está sucediendo debajo, deberá observar sus fundamentos, que se encuentran en la lógica de descripción. Puede encontrar una buena descripción general de la lógica de descripción aquí: http://www.inf.unibz.it/~franconi/dl/course/
Si desea obtener más información sobre RDF, lea el Manual de RDF . RDF Semantics es otra lectura que ruge.
Básicamente, los investigadores han abandonado la parte "semántica" de la web semántica y decidieron centrarse en los datos vinculados: cómo se pueden navegar los tripletes RDF para que podamos perder más ancho de banda de Internet ;-)
La mejor explicación es por ejemplo. Intente buscar en googling para todos los autos que se anuncian en la web con motores de menos de 2.0 litros que funcionan sin plomo, y tenga una conexión de mp3 y se pueda ver en una sala de exposición a la que se puede acceder fácilmente en transporte público desde mi casa.
Google simplemente no podrá ayudarte con esa consulta, no realmente. Tienes que hacer varias búsquedas y correlacionar los resultados por ti mismo. En la web semántica, podría expresar interés en productos para la venta que son automóviles y agregar las restricciones. Todo resultado sería útil. Una o más UI pueden permitirle hacer eso, algunas pueden ser especializadas, otras totalmente genéricas.
Otro ejemplo es crear un cuadro de cosas que normalmente no se almacenan en un solo lugar, por ejemplo, la popularidad del coque dietético o los paseos por el campo en una población en comparación con los niveles de obesidad clínica en la misma población. Para estos, es posible que no utilice un navegador web en absoluto, pero podría usar algo más como Excel , pero la web semántica le brinda herramientas (SPARQL, RDF) para encontrar y manipular los datos que están disponibles y que son accesibles a través de HTTP.
Por lo tanto, el punto señalado por Bravax no es del todo cierto, no mucho puede cambiar, simplemente puede obtener algunos sitios web de mashup más útiles y mejores. O puede que te encuentres haciendo un montón de cosas que nunca pensaste que estuvieran relacionadas con la web antes de hoy.
La web actual tiene muchas alternativas para hacer lo mismo, por ejemplo, GIF animados, Flash, Silverlight, DHTML, etc. Para poner datos en la web semántica habrá una variedad de herramientas y formatos. RDFa es una buena opción, un tipo más general de microformato, pero puede proporcionar un volcado de toda la base de datos, exponer un punto final SPARQL , usar un microformato o una estructura HTML propia y agregar una transformación , habrá muchas herramientas para adaptarse a diferentes casos.
Así que Vartec también tiene razón en parte, puede usar RDFa y eRDF, pero también podría usar muchas otras cosas para publicar datos.
Tenga en cuenta que hay una superposición entre la web semántica y otro concepto de simper llamado Datos vinculados . La forma en que se relacionan entre sí no está clara, pero mi percepción es que la web de Datos Vinculados es lo que necesita antes de que las herramientas y técnicas de la Web Semántica tengan algo que ver. Linked Data trata sobre datos, la web semántica trata más sobre el procesamiento de datos, el razonamiento sobre ellos y el manejo de problemas como la confiabilidad de la confianza y otros. Esencialmente las capas inferiores de la tecnología se acumulan .
La web semántica es la única solución pragmática propuesta hasta ahora para reparar fallas de diseño inherentes de la World Wide Web. Debido a que los diseñadores de Internet, tal como lo conocemos hoy, no proporcionaron mecanismos que aborden los fenómenos lingüísticos fundamentales que gobiernan la forma en que los humanos piensan y se comunican, como la homonimia, la sinonimia, etc. La búsqueda de información en Internet da como resultado una inundación de falsos positivos La idea de la web semántica se reduce a asignar identificadores inequívocos a los recursos web que ayudarán a identificar su significado correctamente. Si tiene éxito un día, es posible que olvidemos cómo era la búsqueda de Google habitual, si falla, todo permanecerá como está ahora.
Tim Berners-Lee lo describe en su blog, Giant Global Graph (desde 2007-11-21):
Tres movimientos mentales:
- Internet : "No son los cables, son las computadoras las que son interesantes"
- Web ( World Wide ): "No son las computadoras, sino los documentos que son interesantes"
- Giant Global Graph : "No son los documentos, son las cosas de las que son importantes"
Sobre el término "Gráfico Global Gigante":
Podemos usar la palabra Graph, ahora, para distinguir de la web.
Llamé a este gráfico la Web semántica, ¡pero tal vez debería haber sido Giant Global Graph! Algo peor que WWWW? ;-) No se ha establecido el término "Web semántica" durante mucho tiempo, no propongo cambiarlo. Pero pensemos en el gráfico que es. (Nota al pie: "Gráfico" también es la palabra que usan las especificaciones RDF, pero así es. Aunque un analizador XML crea un árbol DOM, un analizador RDF crea un gráfico RDF en la memoria).
Actualmente, con las páginas HTML tenemos etiquetas de marcado que describen cómo se debe mostrar el contenido, <b> , '' <pre> , etc. Estas etiquetas no implican ningún significado sobre su contenido.
El concepto de una web semántica es que los documentos contendrían etiquetas XML que implican un significado para su contenido. Por ejemplo, <person><firstname> La gran idea es que CSS podría formatear documentos como estos, pero también sería posible extraer información significativa de estos documentos fácilmente.