c++
¿Qué son las corutinas en C++ 20? (3)
¿Qué son las corutinas en c ++ 20 ?
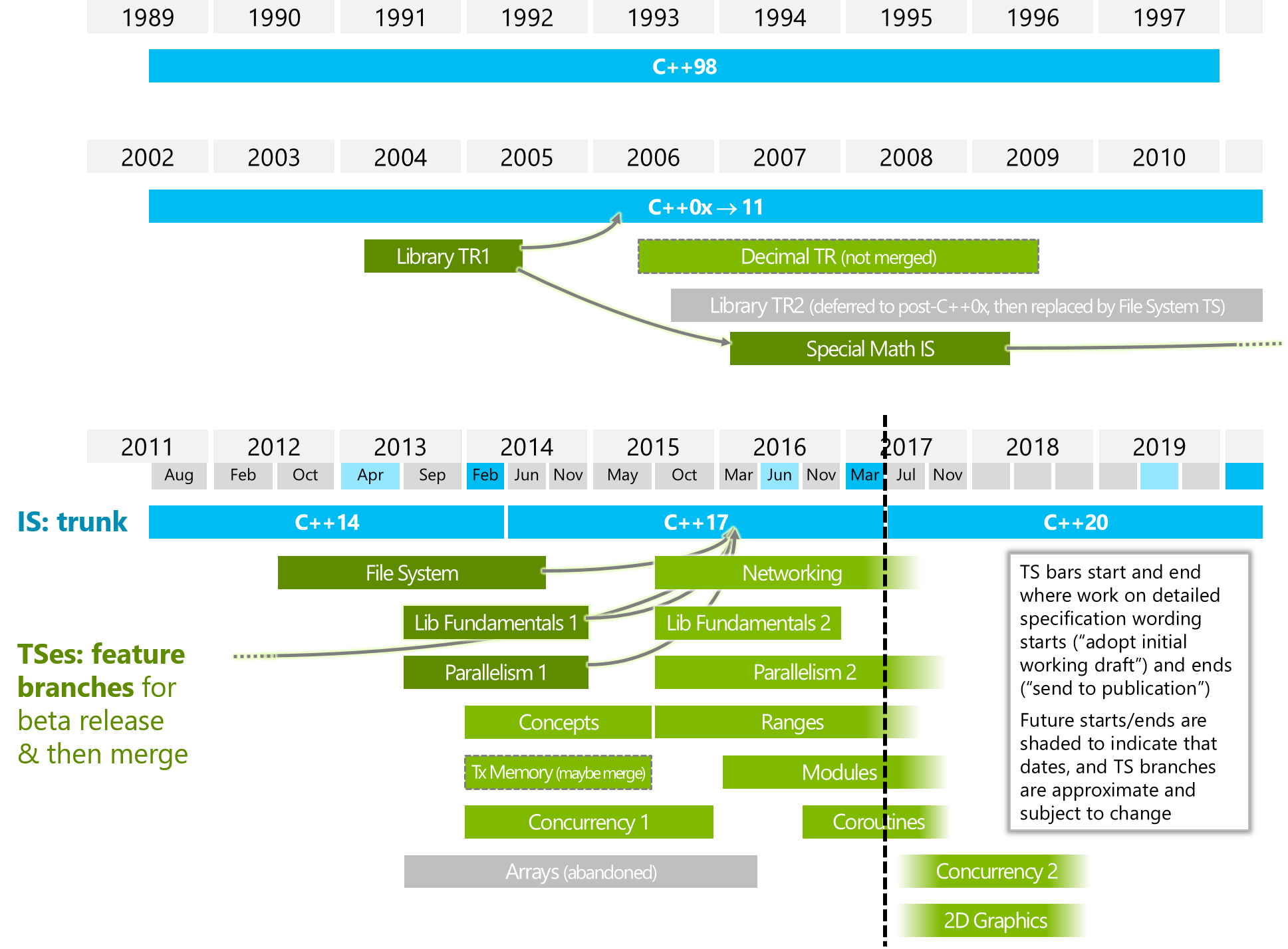
¿De qué manera es diferente de "Parallelism2" o / y "Concurrencia2" (consulte la imagen a continuación)?
La imagen de abajo es de ISOCPP.
{kind=link}
{kind=link}
En un nivel abstracto, Coroutines divide la idea de tener un estado de ejecución fuera de la idea de tener un hilo de ejecución.
SIMD (instrucción única de datos múltiples) tiene múltiples "hilos de ejecución" pero solo un estado de ejecución (solo funciona en múltiples datos). Podría decirse que los algoritmos paralelos son un poco así, ya que tiene un "programa" ejecutado en datos diferentes.
El enhebrado tiene múltiples "hilos de ejecución" y múltiples estados de ejecución. Tiene más de un programa y más de un hilo de ejecución.
Coroutines tiene múltiples estados de ejecución, pero no posee un hilo de ejecución. Tiene un programa y el programa tiene estado, pero no tiene subproceso de ejecución.
El ejemplo más fácil de corutinas son generadores o enumerables de otros idiomas.
En pseudocódigo:
function Generator() {
for (i = 0 to 100)
produce i
}
Se llama al
Generator
, y la primera vez que se llama devuelve
0
.
Se recuerda su estado (cuánto varía con la implementación de las corutinas), y la próxima vez que lo llame, continuará donde lo dejó.
Entonces devuelve 1 la próxima vez.
Entonces 2.
Finalmente llega al final del ciclo y cae al final de la función; La corutina está terminada. (Lo que sucede aquí varía según el lenguaje del que estamos hablando; en Python, arroja una excepción).
Las rutinas traen esta capacidad a C ++.
Hay dos tipos de corutinas; apiladas y sin pilas.
Una rutina de apilamiento solo almacena variables locales en su estado y en su ubicación de ejecución.
Una rutina rutinaria almacena una pila completa (como un hilo).
Las corutinas apiladas pueden ser extremadamente ligeras. La última propuesta que leí implicaba básicamente reescribir su función en algo parecido a una lambda; todas las variables locales entran en el estado de un objeto, y las etiquetas se usan para saltar desde / hacia la ubicación donde la rutina "produce" resultados intermedios.
El proceso de producción de un valor se llama "rendimiento", ya que las corutinas son un poco como el multihilo cooperativo; está devolviendo el punto de ejecución a la persona que llama.
Boost tiene una implementación de rutinas apiladas; le permite llamar a una función para que rinda por usted. Las corutinas apiladas son más poderosas, pero también más caras.
Hay más en las corutinas que un simple generador. Puede esperar una corutina en una corutina, que le permite componer corutinas de manera útil.
Las rutinas, como if, bucles y llamadas a funciones, son otro tipo de "goto estructurado" que le permite expresar ciertos patrones útiles (como las máquinas de estado) de una manera más natural.
La implementación específica de Coroutines en C ++ es un poco interesante.
En su nivel más básico, agrega algunas palabras clave a C ++:
co_return
co_await
co_yield
, junto con algunos tipos de bibliotecas que funcionan con ellos.
Una función se convierte en una rutina al tener uno de esos en su cuerpo. Entonces, desde su declaración, son indistinguibles de las funciones.
Cuando se usa una de esas tres palabras clave en un cuerpo de función, se produce un examen obligatorio estándar del tipo de retorno y los argumentos y la función se transforma en una rutina. Este examen le dice al compilador dónde almacenar el estado de la función cuando la función se suspende.
La rutina más simple es un generador:
generator<int> get_integers( int start=0, int step=1 ) {
for (int current=start; true; current+= step)
co_yield current;
}
co_yield
suspende la ejecución de funciones, almacena ese estado en el
generator<int>
, luego devuelve el valor de la
current
través del
generator<int>
.
Puede recorrer los enteros devueltos.
co_await
tanto,
co_await
permite empalmar una corutina en otra.
Si está en una rutina y necesita los resultados de una cosa esperable (a menudo una rutina) antes de progresar, debe
co_await
.
Si están listos, proceda de inmediato;
si no, se suspende hasta que esté listo el esperado que está esperando.
std::future<std::expected<std::string>> load_data( std::string resource )
{
auto handle = co_await open_resouce(resource);
while( auto line = co_await read_line(handle)) {
if (std::optional<std::string> r = parse_data_from_line( line ))
co_return *r;
}
co_return std::unexpected( resource_lacks_data(resource) );
}
load_data
es una rutina que genera un
std::future
cuando se abre el recurso nombrado y logramos analizar hasta el punto donde encontramos los datos solicitados.
open_resource
y
read_line
s son probablemente corutinas asíncronas que abren un archivo y leen líneas de él.
El
co_await
conecta el estado de suspensión y listo de
load_data
a su progreso.
Las corutinas C ++ son mucho más flexibles que esto, ya que se implementaron como un conjunto mínimo de características de lenguaje además de los tipos de espacio de usuario.
Los tipos de espacio de usuario definen efectivamente lo que
co_return
co_await
y
co_yield
: he visto a personas usarlo para implementar expresiones monádicas opcionales, de modo que un
co_await
en un opcional vacío automáticamente propaga el estado vacío al opcional externo:
modified_optional<int> add( modified_optional<int> a, modified_optional<int> b ) {
return (co_await a) + (co_await b);
}
en vez de
std::optional<int> add( std::optional<int> a, std::optional<int> b ) {
if (!a) return std::nullopt;
if (!b) return std::nullopt;
return *a + *b;
}
Se supone que las corutinas son (en C ++) funciones que pueden "esperar" a que se complete alguna otra rutina y proporcionar lo que sea necesario para que continúe la rutina suspendida, en pausa, en espera. la característica que es más interesante para la gente de C ++ es que las corutinas idealmente no ocuparían espacio en la pila ... C # ya puede hacer algo como esto con esperar y ceder, pero es posible que C ++ deba reconstruirse para obtenerlo.
La simultaneidad se centra en gran medida en la separación de las preocupaciones cuando una preocupación es una tarea que el programa debe completar. Esta separación de preocupaciones puede lograrse por varios medios ... por lo general, puede ser una delegación de algún tipo. La idea de concurrencia es que varios procesos podrían ejecutarse independientemente (separación de preocupaciones) y un ''oyente'' dirigiría lo que sea que se produzca por esas preocupaciones separadas a donde se supone que vaya. Esto depende en gran medida de algún tipo de gestión asincrónica. Existen varios enfoques para la concurrencia, incluida la programación orientada a Aspect y otros. C # tiene el operador ''delegado'' que funciona bastante bien.
el paralelismo suena como concurrencia y puede estar involucrado, pero en realidad es una construcción física que involucra muchos procesadores dispuestos de manera más o menos paralela con un software que puede dirigir porciones de código a diferentes procesadores donde se ejecutará y los resultados se recibirán de vuelta sincrónicamente
Una corutina es como una función C que tiene múltiples declaraciones de retorno y cuando se llama una segunda vez no comienza la ejecución al comienzo de la función, sino en la primera instrucción después del retorno ejecutado anterior. Esta ubicación de ejecución se guarda junto con todas las variables automáticas que vivirían en la pila en funciones no rutinarias.
Una implementación previa de corutina experimental de Microsoft utilizó pilas copiadas para que incluso pudiera regresar de funciones anidadas profundas. Pero esta versión fue rechazada por el comité de C ++. Puede obtener esta implementación, por ejemplo, con la biblioteca de fibra Boosts.